↑

Preview
声明:文档由AI生成,仅作参考,最终功能和计费标准以官方为准。
一、产品概述
Firecrawl 是由 Firecrawl 团队研发的面向开发者的数据抓取与网页解析服务,核心能力是将任意网页内容高质量转换为结构化数据或适用于大模型(LLM)的文本格式。
一句话概括:Firecrawl 提供“抓取 + 清洗 + 结构化”的一体化网页数据获取能力,适用于构建 AI 应用的数据输入层。

二、产品特色
1. 面向 LLM 的网页抓取能力
- 支持将网页自动转换为适合大模型处理的 Markdown / 纯文本格式
- 内置内容清洗能力(去广告、去导航、保留正文语义结构)
- 输出结果更适用于 RAG(检索增强生成)等 AI 场景
2. 多模式抓取接口
- 单页抓取(Scrape):对指定 URL 提取结构化内容
- 整站爬取(Crawl):自动递归抓取站点内部页面
- 深度抓取(Deep Crawl):控制抓取深度与范围
- 支持 sitemap、链接发现等自动化机制
3. 结构化数据输出
-
支持输出:
- Markdown
- HTML
- JSON(结构化字段)
-
可结合 schema 定义,提取特定字段(如标题、正文、元信息等)
4. JavaScript 渲染支持
- 支持抓取 动态网页(SPA / CSR)
- 内置浏览器执行环境(类似 headless browser)
- 可处理依赖 JS 渲染的数据内容(如 React、Vue 页面)
5. AI 增强解析能力
-
支持基于 AI 的内容提取(如语义分块、信息抽取)
-
可与 LLM 工作流结合,用于:
- 文档理解
- 知识库构建
- 自动摘要
6. API 优先设计
- 提供 REST API,便于集成到后端系统
- 支持多语言 SDK(如 JavaScript / Python)
- 支持批量处理与异步任务
7. 抓取控制与过滤能力
-
支持:
- URL 白名单 / 黑名单
- 深度限制
- 页面数量限制
-
可避免无效抓取和资源浪费
8. 高可用与扩展性设计
- 云端托管执行,无需自行部署爬虫基础设施
- 自动处理反爬、请求调度、失败重试等问题
- 支持大规模数据抓取任务
三、收费标准
1. 信息来源说明
以下内容基于官网 Pricing 页面整理,仅做客观呈现。
2. 定价模式概览
Firecrawl 采用 按使用量计费 + 套餐制 的组合模式,核心计费单位为抓取请求或页面处理量。
3. 套餐信息(整理)
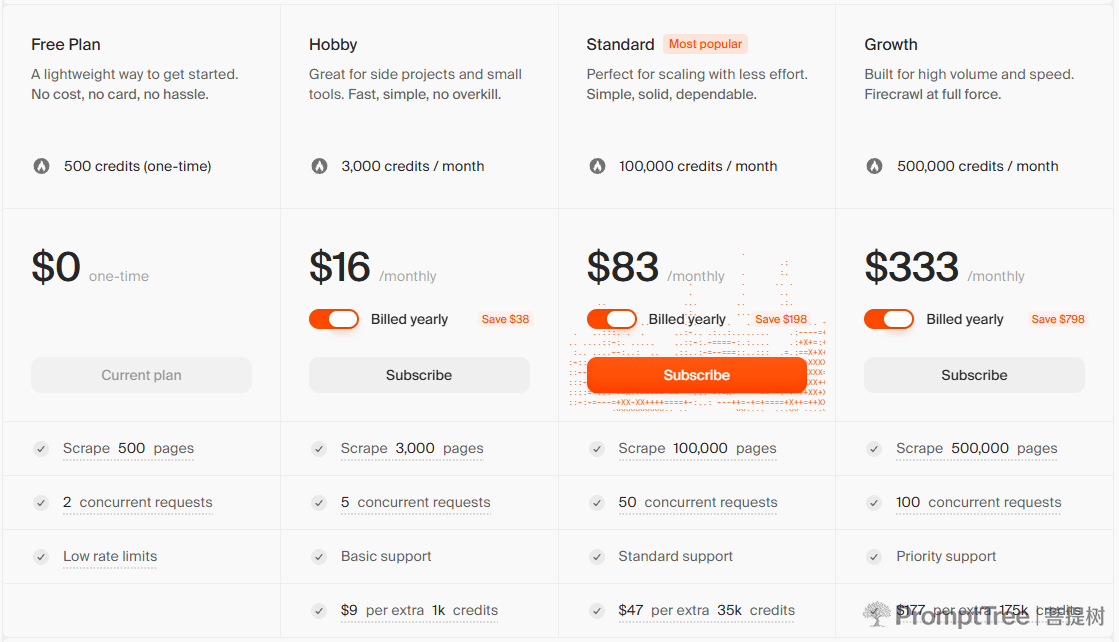
| 套餐类型 | 价格 | 免费额度 | 核心权益 | 适用场景 |
|---|---|---|---|---|
| Free | 免费 | 提供有限免费额度 | 基础抓取能力、API 使用 | 个人测试 / 小规模使用 |
| Pro | 按月订阅(官网公示) | 含一定额度 | 更高请求配额、更快处理速度 | 中小规模应用 |
| Scale / Enterprise | 定制 | 自定义 | 高并发、定制支持、企业级 SLA | 大规模生产环境 |
4. 计费要点
-
主要计费依据:
- 抓取请求数量(requests)
- 页面处理量(pages)
-
不同套餐对应不同:
- 请求上限
- 并发能力
- 处理优先级
注:具体价格数值、额度限制及企业方案需以官网实时数据为准。
四、常见问题
Q:Firecrawl 和传统爬虫工具(如 Scrapy)有什么区别?
A:Firecrawl 提供托管式服务,内置页面解析、清洗和结构化能力,并针对 LLM 场景优化输出;传统爬虫工具通常需要自行处理抓取、解析和清洗流程。
Q:是否支持抓取动态网页?
A:支持。Firecrawl 内置浏览器渲染能力,可以处理依赖 JavaScript 的页面内容。
Q:输出格式是否可控?
A:支持多种格式(Markdown / HTML / JSON),并可通过 schema 控制输出结构。
Q:是否适用于构建 AI 知识库?
A:适用。Firecrawl 的输出格式针对 LLM 优化,可直接用于 RAG、向量数据库等场景。
Q:是否需要自行部署爬虫环境?
A:不需要。Firecrawl 为云服务,负责抓取执行、调度与扩展。
Q:是否有免费额度?
A:有。官网提供 Free 套餐,包含一定的免费使用额度。
Q:如何控制抓取范围?
A:可通过深度限制、URL 过滤规则等方式控制抓取范围。
自检结果:
- 结构完整(概述 / 特色 / 定价 / FAQ)
- 定价信息未虚构,仅做结构化整理
- 功能覆盖抓取、解析、LLM适配等核心能力
- 表格字段规范,无营销性描述
- 未遗漏核心模块(API、渲染、结构化、AI能力)