
声明:文档由AI生成,仅作参考,最终功能和计费标准以官方为准。
一、产品概述
FlagEval(天秤)是北京智源人工智能研究院(BAAI)研发的科学、公正、开放的大模型评测体系及开放平台,旗下包含FlagEval大模型评测平台与FlagEval-Robo具身智能评测平台两大核心板块,可协助研究人员全方位评估基础模型、具身智能模型及训练算法的性能,同时通过AI辅助主观评测提升评测效率与客观性。


二、产品特色
FlagEval大模型评测平台核心特色
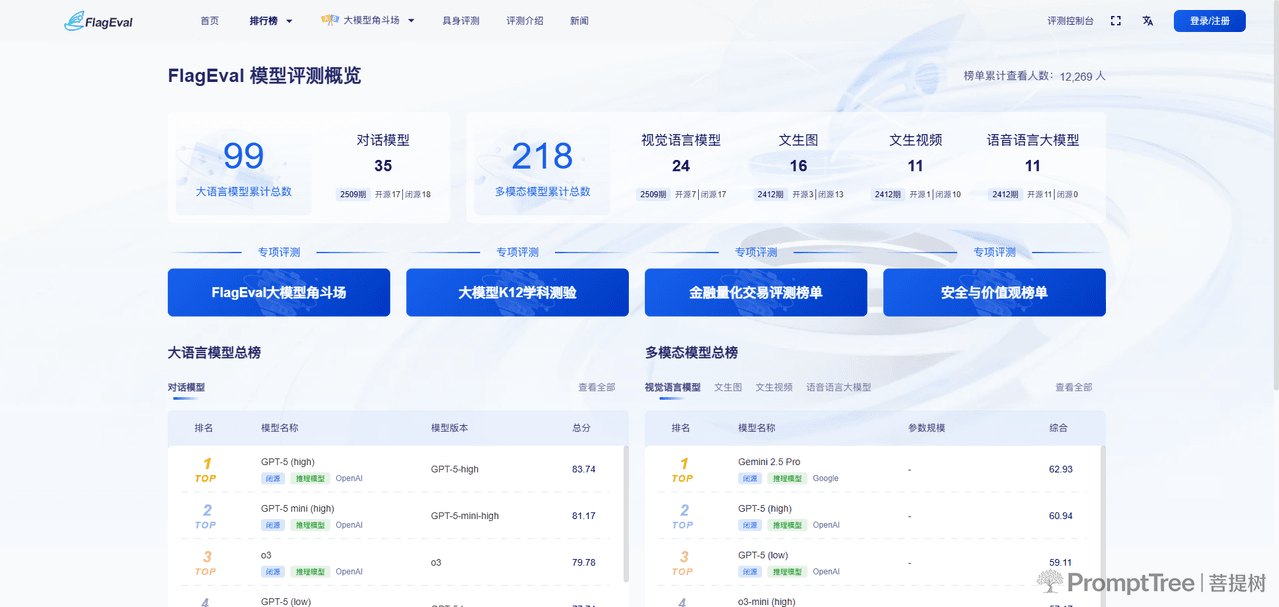
- 构建能力-任务-指标三维评测框架,细粒度刻画基础模型认知能力边界,可视化呈现评测结果。
- 覆盖四大评测领域,包含自然语言处理(NLP)、计算机视觉(CV)、音频(Audio)、多模态(Multimodal),支持超800个开源/闭源模型评测,已完成1010+模型评测工作。
- 提供丰富评测资源,含超22个数据集、8万道评测题目,覆盖30多种能力、5种任务和4大类指标,共超600个评测维度。
- 支持自动化+人工双评测模式,实现主观与客观评测的全自动流水线,同时提供排行榜功能直观展示模型性能。
- 兼容多AI框架(PyTorch、MindSpore)与多硬件架构(NVIDIA、昇腾、寒武纪、昆仑芯等),适配性强。
- 作为智源FlagOpen大模型开源技术体系重要组成,秉持开源开放理念,支持共建共享评测数据集。
FlagEval-Robo具身智能评测平台核心特色
- 专为具身智能打造,支持基准、仿真、实景、物理安全四大评测场景(后三者待上线),可系统化评估具身智能模型的感知、理解与操作能力。
- 支持多模态任务数据采集、上传与标准化处理,实现一测多体、任务驱动、通用泛化的评测特性。
- 基准评测可全面衡量具身智能模型在“感知–理解–表达”与“感知–决策–执行”链条的综合能力,覆盖图像感知、语言指令理解等多模态核心能力。
- 与FlagOS-Robo深度集成,打通具身智能模型从训练、部署到评测的完整链路,支持真机实验和自动化评估。
三、收费标准
官方网站未公示产品收费标准、计费规则及套餐信息,相关资费详情请以官方最新说明为准。
四、常见问题
Q:FlagEval支持哪些类型的模型评测?
A:FlagEval大模型评测平台支持语言大模型、多模态大模型、计算机视觉模型、语音语言大模型的评测;FlagEval-Robo专注于具身智能模型的评测,覆盖不同机器人形态和任务类型。
Q:如何在FlagEval平台提交模型评测任务?
A:首先需注册并登录FlagEval官网,准备好待评测模型文件、推理代码及相关配置文件;安装FlagEval-Serving工具,通过平台获取token后用命令行上传文件;在平台创建评测任务并填写评测领域、模型信息、卡型等参数,提交后平台将自动运行评测流程,完成后可查看详细评测结果。
Q:FlagEval的评测结果以何种形式呈现?
A:评测结果将通过可视化图表、详细性能指标表格、专业分析报告等形式呈现,同时平台提供排行榜功能,直观展示不同模型的性能对比结果。
Q:FlagEval是否支持自定义评测任务?
A:目前FlagEval主要提供标准化的评测任务,针对特殊的定制化评测需求,可与智源研究院进一步沟通探索。
Q:FlagEval与FlagOS-Robo是什么关系?
A:FlagEval-Robo是FlagOS-Robo具身智能训练与推理一体化框架的核心评测组件,FlagOS-Robo训练部署后的具身智能模型,可通过FlagEval-Robo进行集成测试和自动化评估,二者共同构成具身智能模型全生命周期的技术支撑。
Q:FlagEval支持哪些硬件架构?
A:目前支持NVIDIA的A100、A800、V100、T4,寒武纪的MLU370-X8,昆仑芯的R300,以及昇腾的910A等多种硬件架构。