↑

Preview
声明:文档由AI生成,仅作参考,最终功能和计费标准以官方为准。
一、产品概述
AGI-Eval是由上海交通大学、同济大学、华东师范大学、DataWhale等高校和机构联合研发的大模型评测社区与评测框架,核心为大语言模型、多模态模型提供专业、系统的能力评测服务,同时搭建高质量数据集共建平台,助力大模型技术迭代与生态发展。
二、产品特色
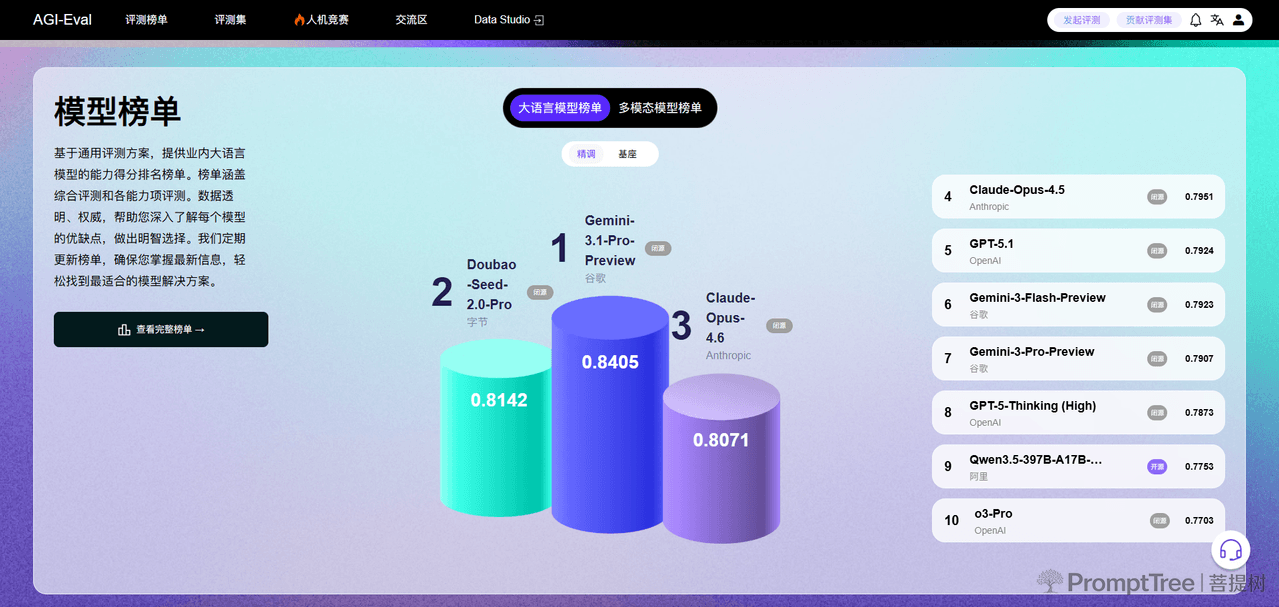
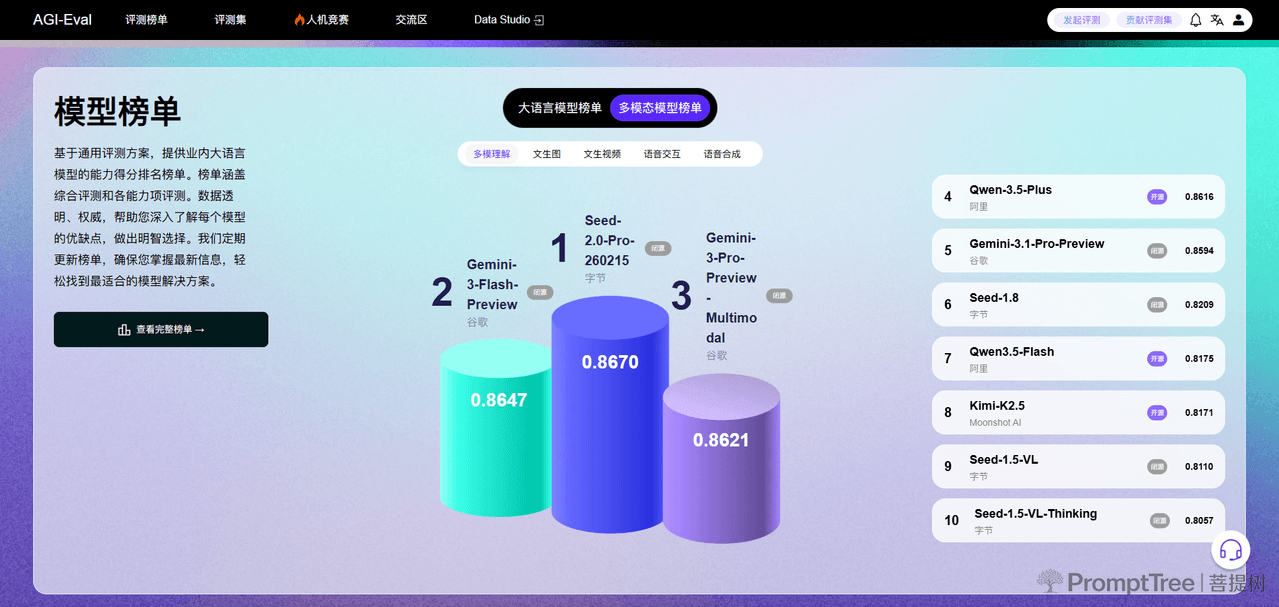
- 提供权威的模型能力排名榜单,涵盖大语言模型、多模态模型两大类型,区分精调、基座维度,榜单包含综合评测与各能力项评测得分,数据透明且定期更新,可清晰呈现各模型优缺点。
- 构建专业的官方评测集,包含OI Bench Preview(代码类)、Math Pro Bench(数学类)等闭源评测集,试题来源为高难度学科竞赛、升学考试真题,由高校合作建设完成。
- 支持人机协同评测模式,用户可参与模型评测过程,共建下一代评测方案,同时能获得相应收益,助力评测标准的完善。
- 搭建AGI-Data数据协同平台,提供模型对话、模型对战、匿名对战三种交互模式,同时设任务广场发布多模态评测任务,覆盖识别、各类推理等多类能力考察。
- 拥有完善的数据集共建体系,支持单条数据、扩写数据、Arena数据等多元收集方式,含500+任务标签的多样数据类型,采用机审+人审的多重审核机制保障数据质量,平台活跃用户超20000+。
- 配套开源的评测框架,基于插件化架构打造,支持单机、本地调试、多进程并行等运行模式,适配20+主流公开数据集,内置Web报告可实现指标统计、模型对比等评测结果洞察。
- 评测框架内置专用打分模型AGI-Eval-OA-Judge,针对唯一答案类数据集实现精准打分,且该打分模型已开源,方便用户复现结果与使用。
- 支持评测开发的灵活扩展,可通过适配框架数据集格式或自定义插件及处理流程两种方式,满足不同的评测开发需求。
三、收费标准
官方网站未公示产品收费标准、计费规则及套餐信息,相关资费详情请以官方最新说明为准。
四、常见问题
Q:AGI-Eval的模型榜单包含哪些模型类型?
A:AGI-Eval的模型榜单主要分为大语言模型榜单和多模态模型榜单,同时榜单会从精调、基座两个维度对模型进行区分展示。
Q:AGI-Eval的官方评测集有哪些?分别考察什么能力?
A:目前主要有两大官方闭源评测集,OI Bench Preview为代码类评测集,由NOIP、信息学竞赛省队选拔赛、NOI等不同难度的信息学算法竞赛题构成;Math Pro Bench为数学类评测集,由全国高中数学联合竞赛、美国数学邀请赛、全国硕士研究生招生考试等数学试题构成。
Q:AGI-Data数据协同平台有哪些交互模式?
A:AGI-Data提供三种核心交互模式,分别为模型对话(选择单个模型发起对话并记录反馈表现)、模型对战(选择两组模型同时会话并记录反馈对战表现)、匿名对战(选择两组匿名模型同时会话并记录反馈对战表现)。
Q:普通用户能否参与AGI-Eval的数据集建设?
A:可以,AGI-Eval搭建了完善的数据集共建体系,支持用户以单条数据、扩写数据等多种方式贡献专业领域数据,且平台配备机审+人审的多重审核机制保障数据质量,用户可参与数据共建并获得相应回报。
Q:AGI-Eval的评测框架对开发者友好吗?
A:友好,评测框架采用插件化、可扩展的架构设计,支持按需拼装各类功能模块,开发者可通过适配框架数据集格式或自定义插件及处理流程两种方式进行评测开发,同时框架支持多种运行模式,可适配不同的机器资源与开发需求。