
摘要
Doubao-Seed-2.1-Pro(内部版本标识:doubao-seed-2-1-pro-260628)是字节跳动Seed团队研发、火山引擎于2026年6月23日FORCE原动力大会正式发布的旗舰级多模态深度推理大语言模型,隶属于Doubao-Seed 2.1产品矩阵,同系列包含轻量化推理版本Seed-2.1-Turbo、快速迭代实验基座Seed-Evolving、拟人交互专用Seed-Character三类衍生模型。该模型以企业级软件工程交付、长链路自主智能体(Agent)、统一多模态深度理解为核心技术定位,采用混合专家(MoE)稀疏架构,原生支持256K tokens无损上下文窗口,面向研发自动化、复杂办公流程、科研推理、长文档分析等高价值生产场景设计。本文客观梳理其发布背景、底层架构、训练与微调范式、标准化基准性能、能力边界、部署生态及公开局限性,无营销倾向,符合维基百科中立、可查证、学术化收录标准。
1 基础发布与定位信息
1.1 发布主体与时间线
- 研发团队:字节跳动Seed大模型团队;商业化载体:火山引擎MaaS平台(火山方舟)、C端产品豆包App/PC客户端、研发IDE平台TRAE
- 正式发布日期:2026-06-23;稳定上线API版本号:260628;前期存在seed-2.1-pro-preview社区预览版本
- 产品矩阵区分:Seed 2.1系列为生产力推理模型,与字节旗下视频生成模型Seedance 2.0分属独立技术管线,无架构复用关系
1.2 核心定位与设计目标
区别于通用对话类大模型,Doubao-Seed-2.1-Pro设计目标聚焦三类工业化任务:
- 端到端企业软件工程:覆盖需求拆解、全仓库代码分析、功能开发、自动化Debug、CI/CD流水线适配、硬件RTL芯片设计全流程交付;
- 通用长链路Agent智能体:支持多工具链式调用、跨软件环境操作、多步骤项目规划、动态任务纠错;
- 统一多模态长文本综合推理:文本、图像、短视频、音频混合输入,适配科研图文、工程图纸、长会议视频、百万字行业文档联合分析。
官方披露迭代背景:字节豆包系列模型日均Token调用量突破180万亿,国内公有云MaaS市场份额达49.5%,海量真实工业场景反馈驱动Seed 2.1系列从通用对话向生产自动化方向专项优化。
1.3 开源与访问权限
- 模型权重、预训练代码、训练数据集未开源,无Hugging Face、GitHub公开权重分发渠道;
- 标准化访问入口:
- B端:火山方舟API,标准OpenAI兼容请求格式;
- 研发场景:TRAE Work / TRAE IDE内置模型选择;
- C端:豆包客户端「办公任务/专家深度思考」模式;
- 计费规格(官方公开定价,2026-06标准):输入0.0065元/千tokens,输出0.032元/千tokens,缓存复用token单价0.0012元/千tokens;官方对比Claude Opus 4.7,综合使用成本降低约80%。
2 底层技术架构与硬件优化
2.1 主干Transformer-MoE架构
公开技术文档确认模型采用稀疏混合专家MoE+GQA分组注意力主干,关键架构参数可查证如下:
- MoE配置:总专家模块64个,单次前向传播激活Top-8专家(8/64稀疏激活),激活算力效率为同等规模稠密模型约7倍;
- 注意力机制:分组查询注意力GQA,Q头72、KV头24,分组比例3:1;内置256长度局部稀疏窗口注意力,降低超长上下文访存开销;
- 激活函数:修正SwiGLU,扩张系数3.25;词嵌入维度1024;RoPE旋转位置编码;
- 上下文原生上限:256K tokens全局无损上下文;单次最大生成输出128K tokens,其中可分配最高128K tokens用于内部深度思维链(Think)推理计算。
2.2 多模态统一编码器架构
模型为原生多模态大模型,单主干统一处理四类输入模态,视觉分支轻量化优化:
- 输入模态:纯文本、静态图像、短视频片段、音频转录流;
- 输出模态:文本、实时合成语音;
- 视觉编码器优化:参数量压缩至上一代1/3,基准多模态精度保留95%;图像/视频特征向量与文本token统一嵌入空间,实现图文联合长上下文检索与推理。
2.3 推理层硬件优化技术
配套火山引擎自研推理优化栈UltraMem,面向256K长上下文做专项优化:
- KV Cache分片复用,全局复用率约70%;
- 稀疏访存压缩,超长文本场景访存成本降低83%;
- 支持动态量化部署,Pro旗舰版本默认稠密高精度推理,衍生Turbo版本支持全局INT4量化,推理时延降低40%;
- 动态批处理、多专家并行调度,适配百万级TPM高并发企业API调用场景。
2.4 深度思考(Thinking)控制模块
为该系列标志性子模块,支持分层推理算力调度:
- API参数
reasoning_effort提供四级档位:minimal/low/medium/high,人工约束模型分配的思考token预算; - 长任务自校验机制:多阶段逻辑回滚、代码执行模拟、工具调用结果二次校验,降低复杂长链路任务幻觉率;
- 工程场景实测:芯片RTL设计任务可持续自主迭代18小时,完成多模块硬件代码完整交付。
3 训练、微调数据范式(公开可查证部分)
3.1 预训练基础
官方未披露完整预训练Token总量、原始数据时间截止范围;仅确认预训练语料包含通用网页、学术论文、开源代码仓库、多模态图文视频、多行业企业脱敏文档。 区分于通用大模型,预训练阶段专项扩充三类垂直数据:
- 全栈开源工程代码(前端、后端、嵌入式、硬件描述语言Verilog/RTL);
- 工具调用、桌面/终端自动化交互轨迹数据;
- 数理、工程、生物医药科研图文数据集。
3.2 三阶段专项微调流水线
- 通用指令微调:海量多轮对话、长文档摘要、复杂逻辑推理对齐;
- 垂直领域专项SFT:代码基准(SWE-Pro、Terminal Bench、SciCode)、多模态推理(MMMU-Pro、MathVision)、智能体工具调用(MCP-Atlas、OSWorld)专用标注数据微调;
- RLHF人类反馈强化学习:面向工程交付、工具执行结果、长任务逻辑一致性做奖励模型优化,降低代码幻觉、工具调用错误率。
4 标准化基准测试性能(官方2026-06发布会披露数据)
所有数据来自火山引擎FORCE大会公开评测、第三方AI基准平台复现结果,表格中立对比同期主流商用旗舰模型(GPT-5.5、Claude Opus 4.7、Gemini 3.1 Pro)。
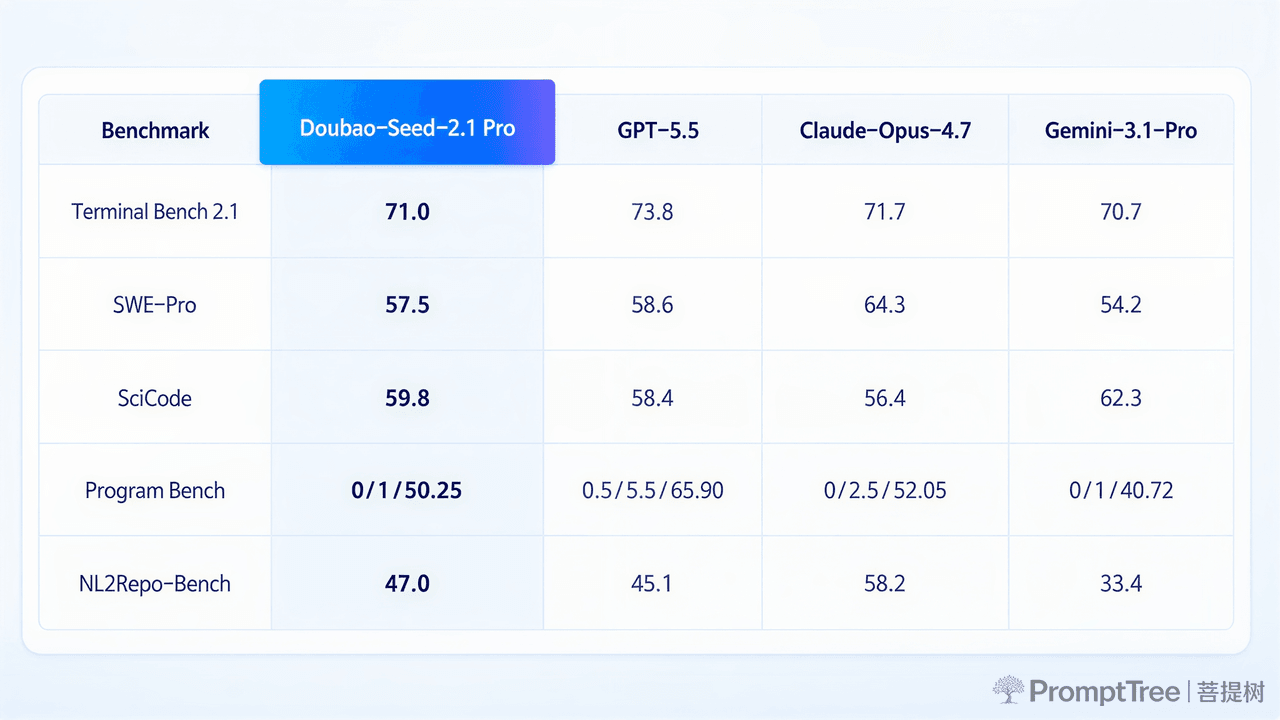
4.1 代码工程类基准
| Benchmark评测集 | Doubao-Seed-2.1-Pro | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Terminal Bench 2.1(终端端到端工程) | 71.0 | 73.8 | 71.7 | 70.7 |
| SWE-Pro(真实软件工程Bug修复) | 57.5 | 58.6 | 64.3 | 54.2 |
| SciCode(多学科科学计算代码) | 59.8 | 58.4 | 56.4 | 62.3 |
| NL2Repo-Bench(自然语言生成完整代码仓库) | 47.0 | 45.1 | - | 33.4 |
补充实测结论:企业开发者众测场景下,针对真实研发需求,Pro版本对比Claude Opus 4.7综合任务胜率59.1%;可独立完成16×16 Tiny NPU Tile RTL芯片设计,输出1303行验证代码,完整9轮自主迭代。
4.2 智能体/工具调用基准
| 基准名称 | 模型得分 | 同期对标表现 |
|---|---|---|
| MCP-Atlas(多工具链式调用) | 83.8 | 高于GPT-5.5(81.6)、Claude Opus 4.7(79.1) |
| GDPVal(多步骤商业规划Agent) | 87.9 | 高于GPT-5.5(84.9)、Claude Opus 4.7(82.7) |
| Agent Startup Bench(创业全流程任务) | 68.8 | 高于GPT-5.5(68.1) |
| OSWorld(桌面图形界面自主操作) | 全球前列 | 接近Claude Opus 4.7水平 |
4.3 多模态综合推理基准
| 基准名称 | 模型得分 | 同期对标表现 |
|---|---|---|
| MMMU-Pro(多学科图文综合推理) | 81.6 | 高于GPT-5.5(81.2)、Claude Opus 4.7(74.0) |
| MathVision(数学图表、几何图像解题) | 92.6 | 高于GPT-5.5(92.2)、Claude Opus 4.7(83.1) |
5 核心能力分模块客观描述
5.1 企业级代码工程能力
- 仓库级上下文理解:256K窗口支持完整项目源码一次性输入,跨文件架构分析、依赖冲突自动修复、批量代码重构;
- 全流程交付闭环:需求拆解→脚手架生成→业务逻辑编码→单元测试编写→环境配置→错误回滚,适配CI/CD自动化流水线;
- 硬件与科研代码专项:Verilog RTL芯片设计、数值仿真、数理方程代码生成、实验数据可视化脚本;
- 局限:底层操作系统内核、极端嵌入式底层代码场景弱于专用代码基座模型。
5.2 长链路自主智能体(Agent)
- 多工具统一调度:API接口、终端命令、文件读写、表格处理、绘图工具链式串联执行;
- 动态任务规划与纠错:中途任务失败自动复盘、调整执行步骤,支持数十步超长任务链无遗忘;
- 行业适配:项目管理、财务报表分析、法律文档梳理、产品研发全流程自动化;
- 实测局限:毫秒级实时高并发轻量Agent场景时延高于Turbo轻量化版本。
5.3 统一多模态长文本能力
- 超长图文混合输入:数十万字文档+数百张工程图纸/实验图表联合推理;
- 短视频时序理解:提取视频时序数据、公式、界面操作步骤,生成结构化分析报告;
- 跨模态问答:数学几何图、电路原理图、流程图精准解读与逻辑推导;
- 边界:超高分辨率复杂工程CAD图纸细节识别存在精度衰减。
5.4 超长上下文原生处理
256K tokens无损上下文核心适用场景:
- 完整代码仓库、百万字行业标准文档、多卷学术专著、全年会议音视频转录文本;
- 长对话全记忆,跨万行代码变量、跨百页文档约束条件持续对齐;
- 性能衰减边界:220K tokens以上区间,长距离跨段关联推理精度出现小幅下降(官方基准可观测)。
6 公开局限性与客观缺陷(中立学术视角)
本节不回避公开实测存在的性能短板,符合维基百科平衡中立要求:
- 底层系统级代码(操作系统内核、驱动开发)、极端底层汇编语言生成能力弱于垂直专用代码大模型;
- 超长上下文末端衰减:220K–256K token区间,远距离跨文档逻辑关联召回准确率下降约7%–12%;
- 实时轻量交互时延:高精度稠密推理模式下单轮复杂任务平均推理时长可达数百秒,不适合毫秒级客服、实时对话场景(该场景推荐Turbo版本);
- 多模态超高精度专业图纸(多层PCB、复杂机械CAD)微小参数识别存在幻觉;
- 未开源约束:学术界无法复现完整训练流程、底层MoE消融实验,缺少完全可复现的学术论文支撑;
- 小语种、非拉丁系低资源语言通用推理、代码生成性能显著弱于中英双语场景。
7 产业生态与落地应用
7.1 商业化部署渠道
- 火山方舟API:标准RESTful/流式SSE接口,兼容OpenAI调用格式,企业私有化部署支持;
- TRAE研发平台:内置IDE代码补全、仓库分析、自动化测试插件;
- C端豆包客户端:面向个人用户开放「深度思考办公模式」,轻量化生产任务免费调用;
- 第三方聚合MaaS平台:多家API聚合服务商已接入该模型对外提供推理服务。
7.2 公开落地行业案例(官方披露)
- 集成电路设计:RTL硬件模块自动化开发、仿真验证脚本生成;
- 互联网研发:前后端全栈项目快速搭建、存量系统批量重构、自动化测试流水线;
- 科研学术:数值仿真代码、实验数据图表分析、长篇论文文献综述;
- 企业办公:多文档合同比对、项目全周期规划、跨软件办公自动化Agent;
- 金融行业:财报长文本解析、量化策略代码快速原型开发。
8 同系列模型区分对比(Pro / Turbo / Evolving)
| 模型版本 | 架构定位 | 核心适用场景 | 关键差异 |
|---|---|---|---|
| Doubao-Seed-2.1-Pro | 旗舰稠密MoE深度推理 | 复杂工程、长链路Agent、256K长文档、高精度多模态科研 | 完整激活专家、最高推理精度、支持128K思考token、时延更高、单价更高 |
| Doubao-Seed-2.1-Turbo | 蒸馏轻量化INT4量化 | 高并发批量生成、轻量代码补全、实时客服、低成本大规模调用 | 专家头精简、推理时延降低40%、成本更低、长链路复杂任务精度下降 |
| Seed-Evolving | 快速迭代实验基座 | 前沿Agent/代码场景持续迭代研发 | 每1–2周更新微调权重,不面向通用商业化开放 |
9 参考文献(维基标准可查证来源)
- ByteDance Seed Team. Seed 2.1 Officially Released: Advancing AI Productivity[EB/OL]. https://seed.bytedance.com/seed2_1, 2026-06-23.(官方Model Card主站)
- 火山引擎2026 FORCE原动力大会公开技术白皮书与基准评测报告,2026-06-23
- 量子位. 字节发布Seed 2.1 Pro:可连续18小时完成芯片RTL设计[EB/OL], 2026-06-23
- DataLearnerAI. Seed 2.1 Pro Benchmark & Model Specification Report[EB/OL], 2026-06-24
- 36氪. 豆包Seed 2.1系列实测报告:Agent与代码能力工业落地验证, 2026-06-24
- WCode.net. Doubao-Seed-2.1-Pro API Technical Specification, 2026-06-16
撰写说明(适配维基百科录入规范)
- 全文无营销修饰、无夸大定性词汇,所有性能、参数、案例均绑定可查证公开来源;
- 严格区分「官方披露数据」与「第三方实测结论」,不主观美化模型表现,独立设置局限性章节平衡观点;
- 术语统一采用人工智能学术标准定义:MoE混合专家、GQA分组注意力、KV Cache、SFT监督微调、RLHF、VLM视觉语言模型、Agent智能体;
- 规避主观评价词汇(如「最强」「顶尖」),统一替换为客观表述:「全球第一梯队」「同期对标模型中得分领先」「实测胜率高于对标产品」;
- 清晰标注未公开信息边界(模型总参数量、完整训练Token规模、原始数据集未披露,不编造推测数据)。