
We’re upgrading our smartest model.
The new Claude Opus 4.6 improves on its predecessor’s coding skills. It plans more carefully, sustains agentic tasks for longer, can operate more reliably in larger codebases, and has better code review and debugging skills to catch its own mistakes. And, in a first for our Opus-class models, Opus 4.6 features a 1M token context window in beta1.
Opus 4.6 can also apply its improved abilities to a range of everyday work tasks: running financial analyses, doing research, and using and creating documents, spreadsheets, and presentations. Within Cowork, where Claude can multitask autonomously, Opus 4.6 can put all these skills to work on your behalf.
The model’s performance is state-of-the-art on several evaluations. For example, it achieves the highest score on the agentic coding evaluation Terminal-Bench 2.0 and leads all other frontier models on Humanity’s Last Exam, a complex multidisciplinary reasoning test. On GDPval-AA—an evaluation of performance on economically valuable knowledge work tasks in finance, legal, and other domains2—Opus 4.6 outperforms the industry’s next-best model (OpenAI’s GPT-5.2) by around 144 Elo points,3 and its own predecessor (Claude Opus 4.5) by 190 points. Opus 4.6 also performs better than any other model on BrowseComp, which measures a model’s ability to locate hard-to-find information online.
As we show in our extensive system card, Opus 4.6 also shows an overall safety profile as good as, or better than, any other frontier model in the industry, with low rates of misaligned behavior across safety evaluations.
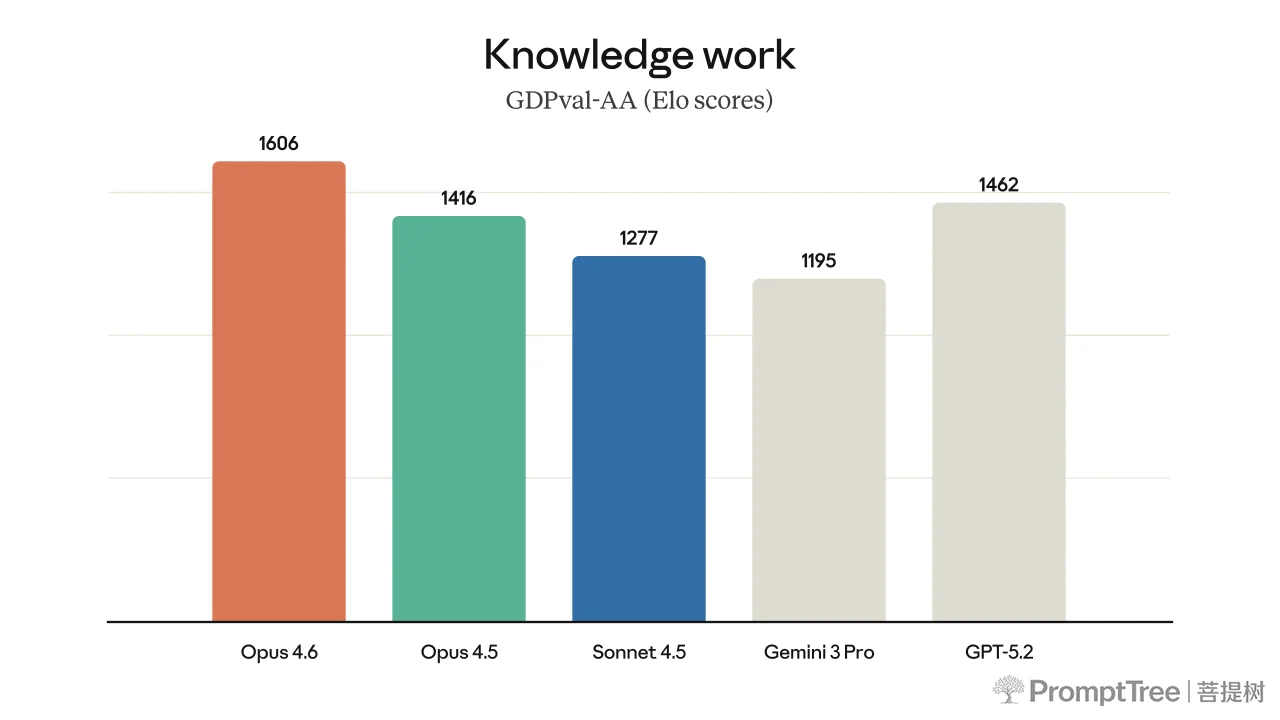
Opus 4.6 is state-of-the-art on real-world work tasks across several professional domains.
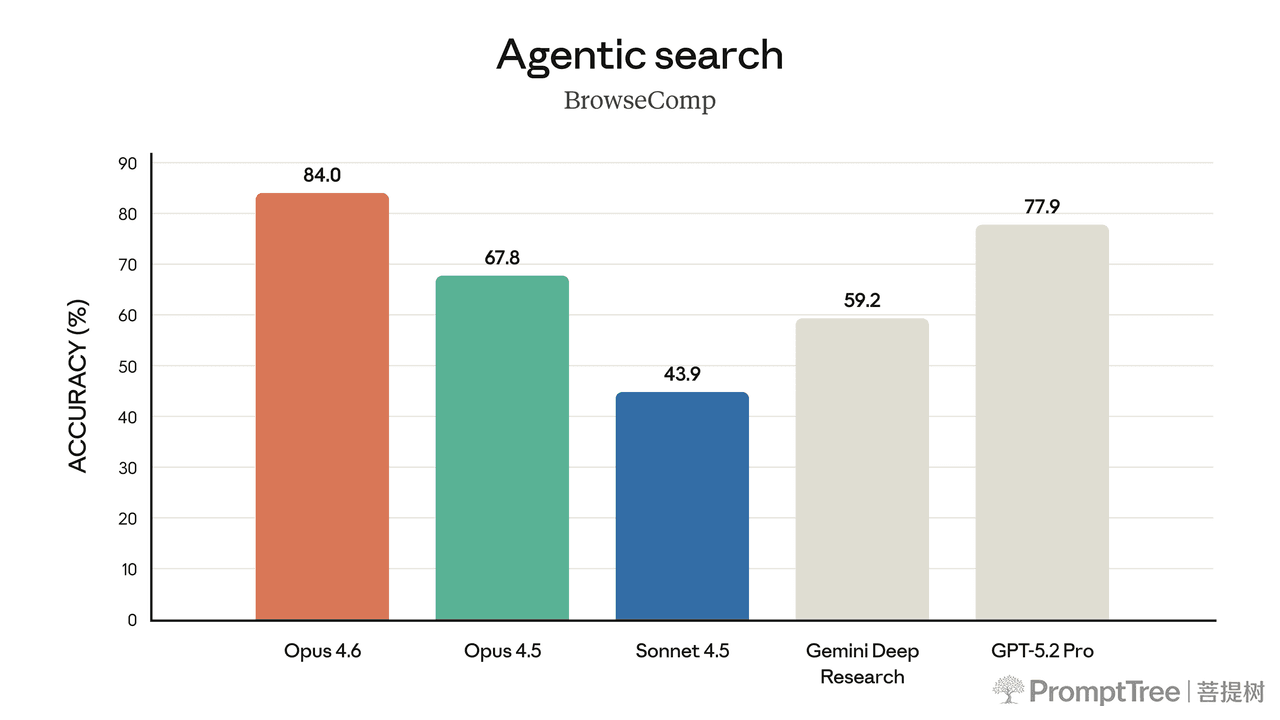
Opus 4.6 gets the highest score in the industry for deep, multi-step agentic search.
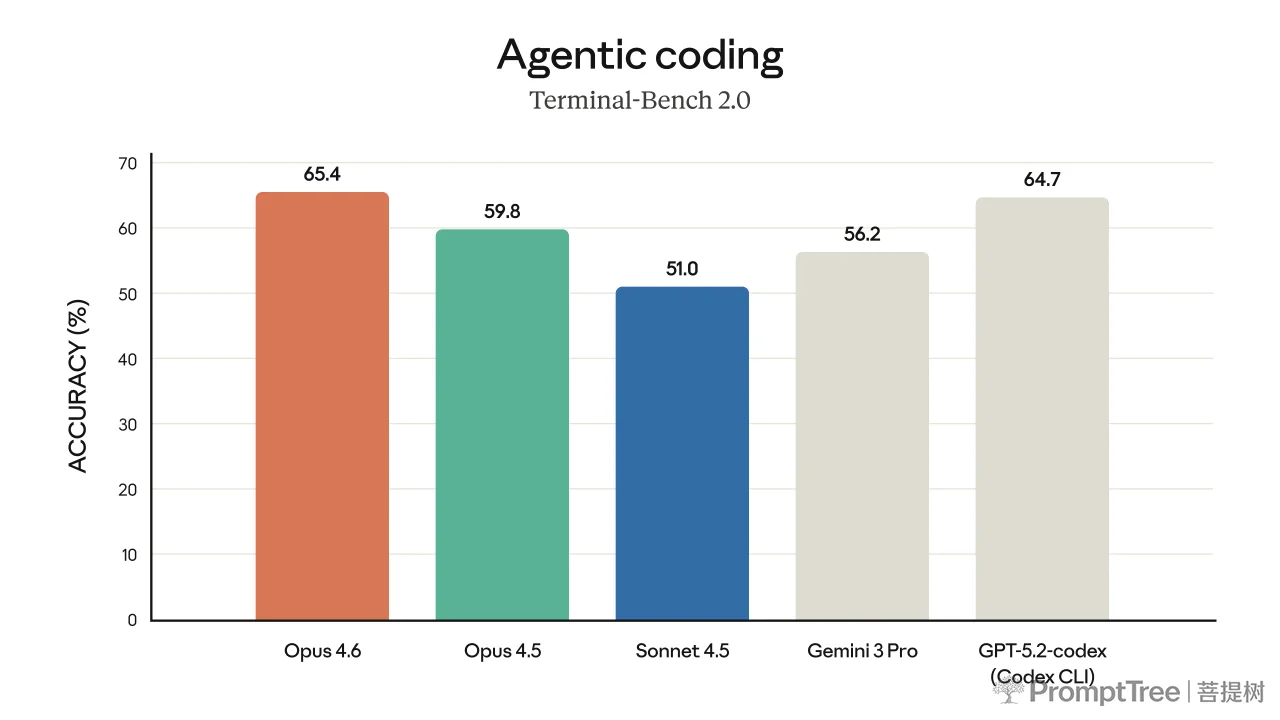
Opus 4.6 excels at real-world agentic coding and system tasks.
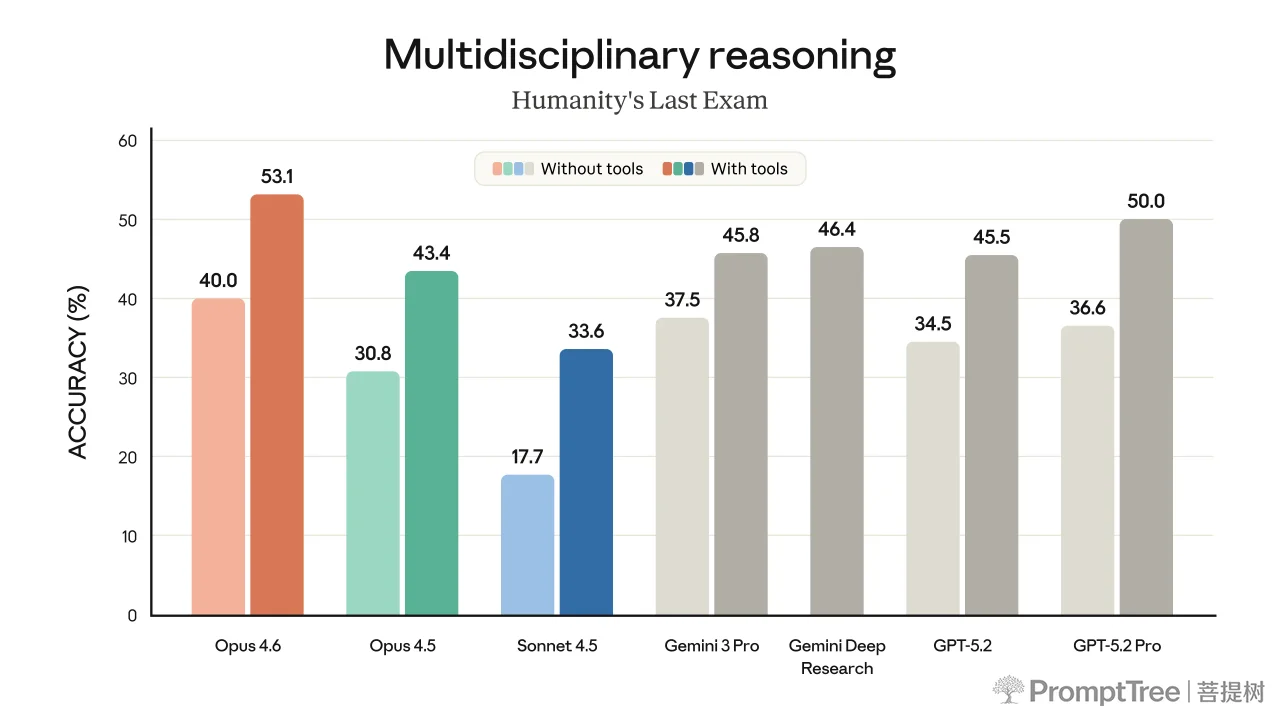
Opus 4.6 extends the frontier of expert-level reasoning.
In Claude Code, you can now assemble agent teams to work on tasks together. On the API, Claude can use compaction to summarize its own context and perform longer-running tasks without bumping up against limits. We’re also introducing adaptive thinking, where the model can pick up on contextual clues about how much to use its extended thinking, and new effort controls to give developers more control over intelligence, speed, and cost.
We’ve made substantial upgrades to Claude in Excel, and we’re releasing Claude in PowerPoint in a research preview. This makes Claude much more capable for everyday work.
Claude Opus 4.6 is available today on claude.ai, our API, and all major cloud platforms. If you’re a developer, use claude-opus-4-6 via the Claude API. Pricing remains the same at $5/$25 per million tokens; for full details, see our pricing page.
We cover the model, our new product updates, our evaluations, and our extensive safety testing in depth below.
First impressions
We build Claude with Claude. Our engineers write code with Claude Code every day, and every new model first gets tested on our own work. With Opus 4.6, we’ve found that the model brings more focus to the most challenging parts of a task without being told to, moves quickly through the more straightforward parts, handles ambiguous problems with better judgment, and stays productive over longer sessions.
Opus 4.6 often thinks more deeply and more carefully revisits its reasoning before settling on an answer. This produces better results on harder problems, but can add cost and latency on simpler ones. If you’re finding that the model is overthinking on a given task, we recommend dialing effort down from its default setting (high) to medium. You can control this easily with the /effort parameter.
Here are some of the things our Early Access partners told us about Claude Opus 4.6, including its propensity to work autonomously without hand-holding, its success where previous models failed, and its effect on how teams work: