
Introducing MiMo-V2.5
Today, we are releasing MiMo-V2.5, a major step forward in agentic capability and multimodal understanding. With native visual and audio understanding, MiMo-V2.5 reasons seamlessly across modalities, surpasses MiMo-V2-Pro in agentic performance, and supports up to 1 million tokens of context.
MiMo-V2.5 is a 310B-parameter Sparse MoE model (15B active) trained on 48T tokens. Its language backbone inherits from MiMo-V2-Flash's hybrid sliding-window attention architecture, augmented with dedicated visual and audio encoders (both pretrained in-house) connected through lightweight projectors.

Training goes through five stages: text pre-training on diverse corpora to build the LLM backbone; projector warmup to align the audio and visual projectors with the language model; multimodal pre-training at scale on high-quality cross-modal data; supervised fine-tuning and agentic post-training, during which the context window is progressively extended from 32K to 256K to 1M; and finally RL and MOPD, which further strengthens perception, reasoning, and agentic capabilities.
Together, these stages yield a single model that sees, hears, and acts on what it perceives — one that understands everything and gets things done.
Best-in-Class Agency
On the agentic benchmarks that matter most for real-world deployment, MiMo-V2.5 delivers best-in-class performance:
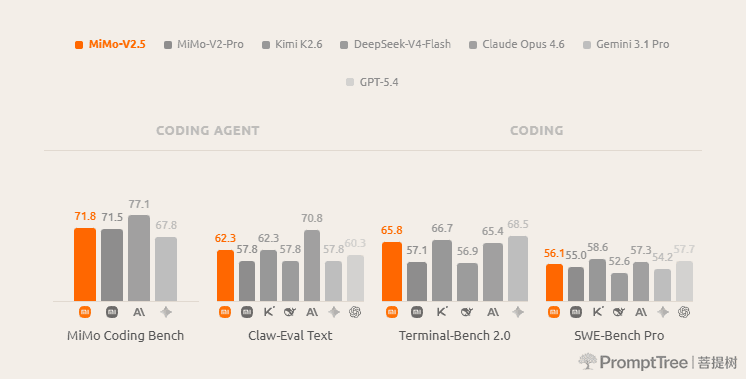
In our internal MiMo Coding Bench, MiMo-V2.5 delivers strong results on everyday coding tasks, closing the gap with frontier models and matching MiMo-V2.5-Pro at half the cost.
On Claw-Eval, a benchmark for daily agentic tasks, MiMo-V2.5 achieves a 62.3 on the general subset, placing it at the Pareto frontier of performance and efficiency.
These results highlight what makes MiMo-V2.5 unique: frontier-level agentic capability with high token efficiency.
Sharper Perception, Longer Horizon
MiMo-V2.5 delivers sharper perception for precise visual reasoning, complex chart analysis, and deep multimodal understanding, with native support for up to 1 million tokens of context.
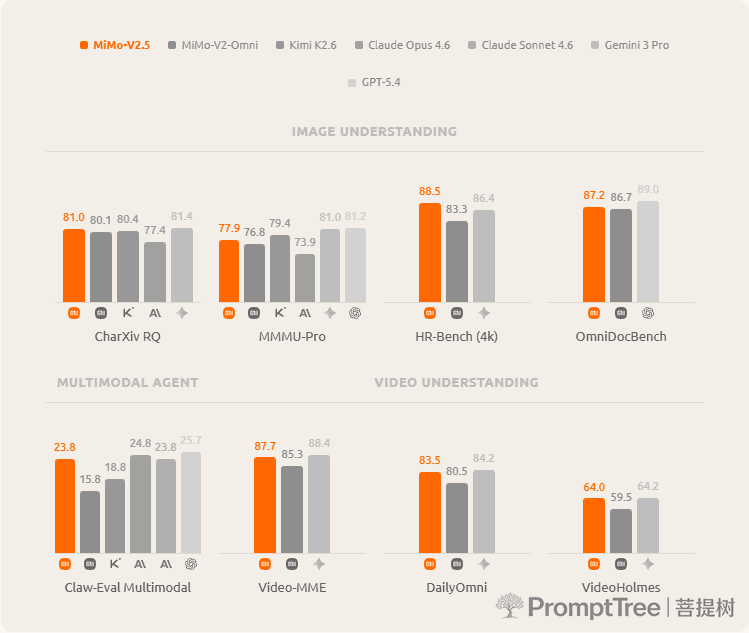
Across image, video, and multimodal agentic tasks, MiMo-V2.5 stays level with frontier closed-source models — matching Gemini 3 Pro on video, Claude Sonnet 4.6 on multimodal agentic work, and staying competitive across image and document understanding. All from one unified model.
Open Source
The MiMo-V2.5 series is now fully open-sourced. Weights, tokenizer, and the full model card are available on Hugging Face.
| Model | Total Params | Active Params | Context | Precision | Download |
|---|---|---|---|---|---|
| MiMo-V2.5-Base | 310B | 15B | 256K | FP8 (E4M3) Mixed | Hugging Face |
| MiMo-V2.5 | 310B | 15B | 1M | FP8 (E4M3) Mixed | Hugging Face |
Token Plan Update
Alongside stronger models, your Token Plan gets better too. Rates are now simpler and lower:
- MiMo-V2.5 — 1x (1 token = 1 credit)
- MiMo-V2.5-Pro — 2x (1 token = 2 credits)
From today onward, Token Plans no longer charge a multiplier for the 1M-token context window. Order your Token Plan now.
What's Next
MiMo-V2.5 brings frontier agency and native multimodality into the same model, at a price point that makes both practical for production. We are already training the next generation with deeper reasoning, tighter tool integration, and richer real-world grounding. In the meantime, try it in AI Studio or access the API — we cannot wait to see what you build.