
Xiaomi MiMo-V2.5-Pro
A leap in agentic and long horizon coherence.
Today, we are releasing and open-sourcing MiMo-V2.5-Pro. It is our most capable model to date, delivering significant improvements over its predecessor, MiMo-V2-Pro, in general agentic capabilities, complex software engineering, and long-horizon tasks. MiMo-V2.5-Pro is a 1.02T-parameter Mixture-of-Experts model with 42B active parameters, built on a hybrid-attention architecture with a 1M-token context window.
In internal testing, V2.5-Pro demonstrated a new level of intelligence that, in turn, pushed our researchers to rethink how they work with it. When paired with a proper harness, V2.5-Pro can sustain complex, long-horizon tasks spanning more than a thousand tool calls. We also see substantial improvements in instruction following within agentic scenarios. It reliably adheres to subtle requirements embedded in context and maintains strong coherence across ultra-long contexts.
MiMo-V2.5-Pro is now fully rolled out across our API Platform, AI Studio, and other surfaces, with no change in pricing. Simply replace the model tag with mimo-v2.5-pro to get started.
Built to Solve Harder
MiMo-V2.5-Pro is built for harder goals. We've given it tasks that would take human experts days or weeks, and let it run autonomously. Here's what it delivers:
SysY Compiler in Rust
Sourced from Peking University's Compiler Principles course project, this task asks the model to implement a complete SysY compiler in Rust from scratch: lexer, parser, AST, Koopa IR codegen, RISC-V assembly backend, and performance optimization. The reference project typically takes a PKU CS major student several weeks. MiMo-V2.5-Pro finished in 4.3 hours across 672 tool calls, scoring a perfect 233/233 against the course's hidden test suite.
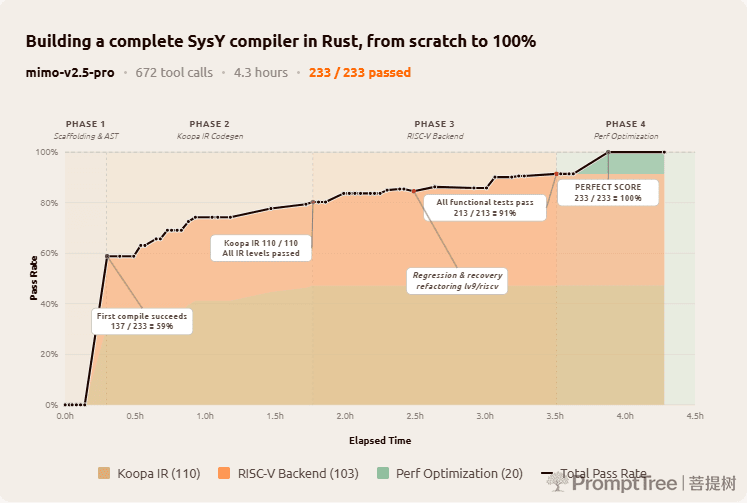
Rather than thrashing through trial and error, the model built the compiler layer by layer: scaffold the full pipeline first, perfect Koopa IR (110/110), then the RISC-V backend (103/103), then performance (20/20). The first compile alone passed 137/233 tests, a 59% cold start that suggests the architecture was designed correctly before a single test was run. At turn 512 a refactoring pass regressed lv9/riscv by two tests; the model diagnosed the failures, recovered, and pushed on. Long-horizon work rewards this kind of structured, self-correcting discipline.
A Full-Featured Video Editor
With just a few simple prompts, MiMo-V2.5-Pro delivered a working desktop app: multi-track timeline, clip trimming, cross-fades, audio mixing, and export pipeline. The final build is 8,192 lines of code, produced over 1,868 tool calls across 11.5 hours of autonomous work.
A demo of the video editor MiMo-V2.5-Pro wrote end-to-end, including AI voice-over driven by MiMo-V2-TTS.
Analog EDA: FVF-LDO Design & Optimization
A graduate-level analog-circuit EDA task: design and optimize a complete FVF-LDO (Flipped-Voltage-Follower low-dropout regulator) from scratch in the TSMC 180nm CMOS process. The model has to size the power transistor, tune the compensation network, and pick bias voltages so that six metrics land within spec simultaneously — phase margin, line regulation, load regulation, quiescent current, PSRR, and transient response. A trained analog designer typically spends several days on a project of this scope.
We wired MiMo-V2.5-Pro into an ngspice simulation loop with Claude Code as the harness. In about an hour of closed-loop iteration — calling the simulator, reading waveforms, tweaking parameters — the model produced a design where every target metric is met, and the four shown below are improved by an order of magnitude over its own initial attempt.

Throughout these experiments, V2.5-Pro exhibits a remarkable "harness awareness": it makes full use of the affordances of its harness environment, manages its memory, and shapes how its own context is populated toward the final objective.
Frontier Coding Intelligence
We further advanced the model's coding intelligence by scaling post-training compute.
MiMo Coding Bench is our in-house evaluation suite for assessing models' ability to handle diverse coding tasks within agentic frameworks such as Claude Code. It covers repo understanding, project building, code review, structured artifact generation, planning, SWE, and more. MiMo-V2.5-Pro further enhances the user experience in real-world coding scenarios, better handling a wide variety of development needs.
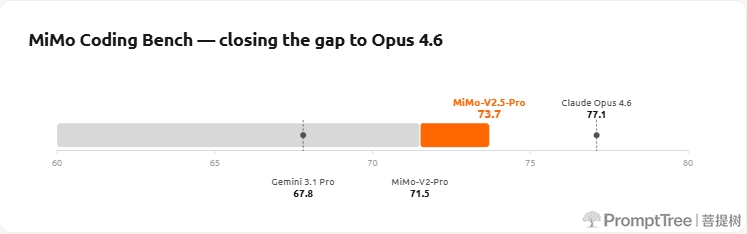
We welcome developers worldwide to integrate MiMo-V2.5 series into scaffolds such as Claude Code, OpenCode, and Kilo — accessing top-tier intelligence at a lower cost.
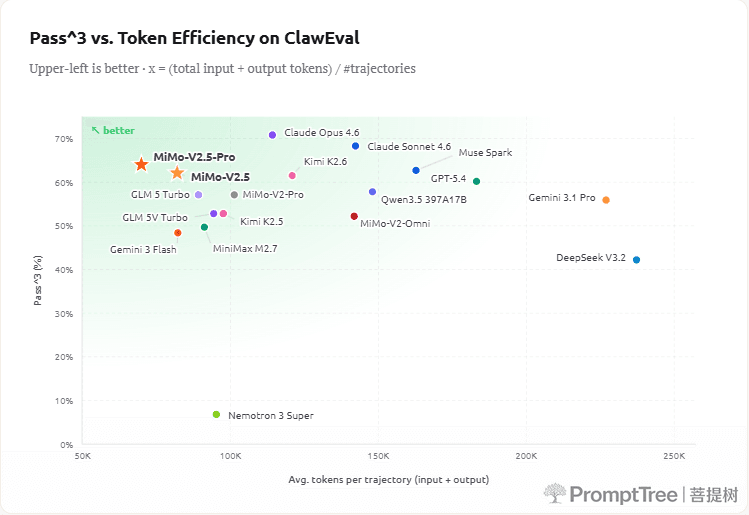
Token Efficiency
Higher intelligence isn't just about higher scores — it's about getting there with fewer tokens. MiMo-V2.5-Pro reaches frontier-tier capability while spending dramatically less on tokens per trajectory. On ClawEval, V2.5-Pro lands at 64% Pass^3 using only ~70K tokens per trajectory — roughly 40–60% fewer tokens than Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.4 at comparable capability levels. The upper-left corner of the chart is where you want to be: higher score for lower cost.
Token Plan Updates
Alongside a stronger model, we've also upgraded our inference infrastructure. The Token Plan now comes with a few meaningful improvements:

All users who purchased a Token Plan before 14:00 UTC on April 21 will have their used Credit balance reset.
Open Source
MiMo-V2.5-Pro is now fully open-sourced under a permissive license. Weights, tokenizer, and the full model card are available on Hugging Face.
Model specifications
| Model | Total Params | Active Params | Context | Precision | Download |
|---|---|---|---|---|---|
| MiMo-V2.5-Pro-Base | 1.02T | 42B | 256K | FP8 (E4M3) Mixed | Hugging Face |
| MiMo-V2.5-Pro | 1.02T | 42B | 1M | FP8 (E4M3) Mixed | Hugging Face |
Architecture & training
MiMo-V2.5-Pro inherits the hybrid attention and Multi-Token Prediction (MTP) design from MiMo-V2-Flash. Local Sliding Window Attention (SWA) and Global Attention (GA) are interleaved at a 6:1 ratio with a 128-token window, which cuts KV-cache storage by nearly 7× at long context while preserving performance through a learnable attention-sink bias. A lightweight MTP module with dense FFNs is natively integrated for training and inference, roughly tripling output throughput and accelerating RL rollouts.
Pre-training runs on 27T tokens using FP8 mixed precision at a native 32K sequence length, with context extended up to 1M tokens. Post-training follows the three-stage paradigm introduced in MiMo-V2-Flash: (1) Supervised Fine-Tuning to establish foundational instruction following on curated data pairs; (2) Domain-Specialized Training, where separate teacher models are each optimized via domain-specific RL across math, safety, agentic tool-use, and more; and (3) Multi-Teacher On-Policy Distillation (MOPD), where a single student model learns on-policy from its own rollouts under token-level guidance from every specialist teacher, merging their capabilities into one unified model.
See the model card on Hugging Face for architecture details, evaluation tables, and deployment guides for SGLang and vLLM.
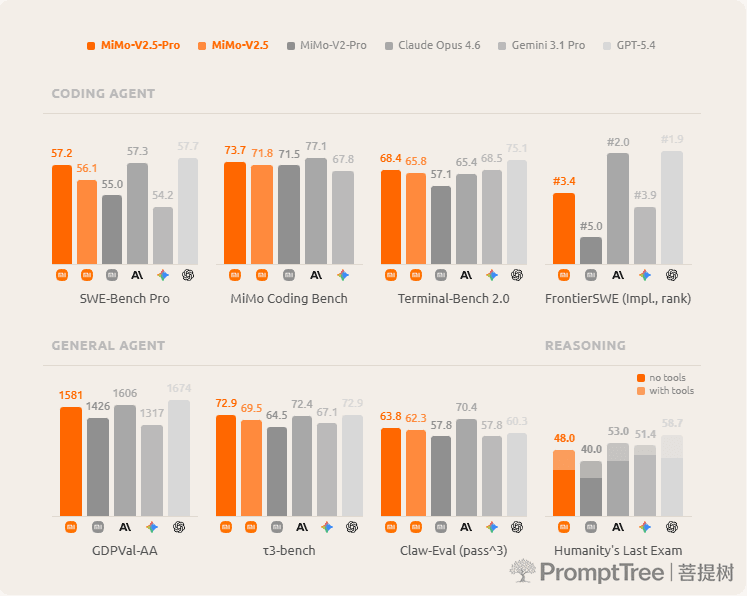
Full benchmark results
Legend: Best open-source | Best overall
| Benchmark | MiMo-V2.5-Pro (1.02T / 42B) | MiMo-V2-Pro (1.02T / 42B) | DeepSeek V4 Pro (1.6T / 49B) | Kimi K2.6 (1T / 32B) | GLM 5.1 (744B / 40B) | Gemini 3.1 Pro | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|---|---|---|---|---|---|
| General Agent | ||||||||
| GDPVal-AA (Elo) | 1581 | 1426 | 1554 | 1480 | 1535 | 1317 | 1674 | 1606 |
| τ³-bench | 72.9 | 64.5 | 71.8 | 71.0 | 70.6 | 67.1 | 72.9 | 72.4 |
| Claw-Eval (pass^3) | 63.8 | 57.8 | 59.8 | 62.3 | 62.7 | 57.8 | 60.3 | 70.4 |
| Humanity's Last Exam (w.o. tools / with tools) | 48.0 / 34.0 | 40.0 / 28.0 | 48.2 / 37.7 | 54.0 / 34.7 | 52.3 / 31.0 | 51.4 / 44.4 | 58.7 / 42.7 | 53.0 / 40.0 |
| Coding Agent | ||||||||
| SWE-Bench Pro | 57.2 | 55.0 | 55.4 | 58.6 | 58.4 | 54.2 | 57.7 | 57.3 |
| SWE-bench Verified | 78.9 | 78.0 | 80.6 | 80.2 | — | 76.2 | — | 80.8 |
| Terminal-Bench 2.0 | 68.4 | 57.1 | 67.9 | 66.7 | 69.0 | 68.5 | 75.1 | 65.4 |
| FrontierSWE (Impl.) | #3.4 | #5.0 | — | — | — | #3.9 | #1.9 | #2.0 |
Higher is better unless marked (rank). "—" = not evaluated. DeepSeek V4 Pro numbers are with its max effort setting.