↑

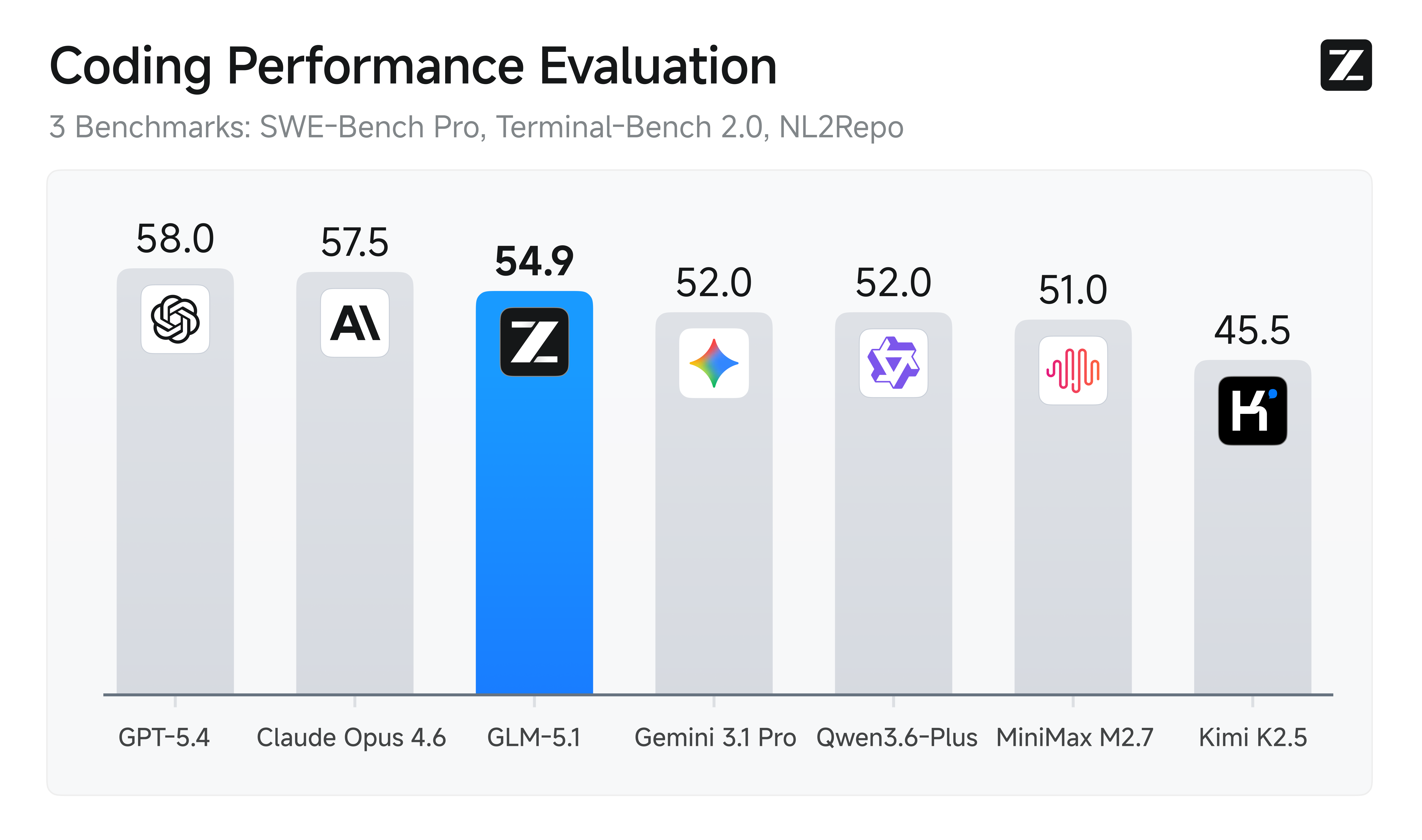
GLM-5.1 是 Z.AI 面向智能体工程打造的下一代旗舰模型,其编码能力较前代显著增强。该模型在 SWE-Bench Pro 上达到业界领先水平,并在 NL2Repo(仓库生成)与 Terminal-Bench 2.0(真实终端任务)上以大幅优势领先 GLM-5。
但最具意义的飞跃远不止于首次执行的表现。此前包括 GLM-5 在内的模型往往过早耗尽策略:它们会运用熟悉的技术快速取得初步收益,随后便陷入平台期。即使给予更多时间也无济于事。
相比之下,GLM-5.1 专为在更长的时间跨度内保持智能体任务的有效性而设计。我们发现,该模型能以更优的判断力处理模糊问题,并在更长的会话周期中保持高效产出。它能分解复杂问题、运行实验、读取结果,并以极高的精度识别障碍。通过反复迭代审视推理过程并修正策略,GLM-5.1 可在数百轮交互与数千次工具调用中持续优化。运行时间越长,效果越佳。
基准测试
| GLM-5.1 | GLM-5 | Qwen3.6-Plus | Minimax M2.7 | DeepSeek-V3.2 | Kimi K2.5 | Claude Opus 4.6 | Gemini 3.1 Pro | GPT-5.4 | |
|---|---|---|---|---|---|---|---|---|---|
| HLE | 31.0 | 30.5 | 28.8 | 28.0 | 25.1 | 31.5 | 36.7 | 45.0 | 39.8 |
| HLE(带工具) | 52.3 | 50.4 | 50.6 | - | 40.8 | 51.8 | 53.1* | 51.4* | 52.1* |
| AIME 2026 | 95.3 | 95.4 | 95.1 | 89.8 | 95.1 | 94.5 | 95.6 | 98.2 | 98.7 |
| HMMT 2025年11月 | 94.0 | 96.9 | 94.6 | 81.0 | 90.2 | 91.1 | 96.3 | 94.8 | 95.8 |
| HMMT 2026年2月 | 82.6 | 82.8 | 87.8 | 72.7 | 79.9 | 81.3 | 84.3 | 87.3 | 91.8 |
| IMOAnswerBench | 83.8 | 82.5 | 83.8 | 66.3 | 78.3 | 81.8 | 75.3 | 81.0 | 91.4 |
| GPQA-Diamond | 86.2 | 86.0 | 90.4 | 87.0 | 82.4 | 87.6 | 91.3 | 94.3 | 92.0 |
| SWE-Bench Pro | 58.4 | 55.1 | 56.6 | 56.2 | - | 53.8 | 57.3 | 54.2 | 57.7 |
| NL2Repo | 42.7 | 35.9 | 37.9 | 39.8 | - | 32.0 | 49.8 | 33.4 | 41.3 |
| Terminal-Bench 2.0(Terminus-2) | 63.5 | 56.2 | 61.6 | - | 39.3 | 50.8 | 65.4 | 68.5 | - |
| Terminal-Bench 2.0(最佳自报成绩) | 66.5(Claude Code) | 56.2(Claude Code) | - | 57.0(Claude Code) | 46.4(Claude Code) | - | - | - | 75.1(Codex) |
| CyberGym | 68.7 | 48.3 | - | - | 17.3 | 41.3 | 66.6 | - | - |
| BrowseComp | 68.0 | 62.0 | - | - | 51.4 | 60.6 | - | - | - |
| BrowseComp(带上下文管理) | 79.3 | 75.9 | - | - | 67.6 | 74.9 | 84.0 | 85.9 | 82.7 |
| τ³-Bench | 70.6 | 69.2 | 70.7 | 67.6 | 69.2 | 66.0 | 72.4 | 67.1 | 72.9 |
| MCP-Atlas(公开集) | 71.8 | 69.2 | 74.1 | 48.8 | 62.2 | 63.8 | 73.8 | 69.2 | 67.2 |
| Tool-Decathlon | 40.7 | 38.0 | 39.8 | 46.3 | 35.2 | 27.8 | 47.2 | 48.8 | 54.6 |
| Vending Bench 2 | $5,634.00 | $4,432.12 | $5,114.87 | - | $1,034.00 | $1,198.46 | $8,017.59 | $911.21 | $6,144.18 |