↑

概述
 Qwen3 是 Qwen 系列中最新一代大型语言模型,提供了一套全面的密集和混合专家 (MoE) 模型。
Qwen3 是 Qwen 系列中最新一代大型语言模型,提供了一套全面的密集和混合专家 (MoE) 模型。
旗舰模型Qwen3-235B-A22B在编码、数学、通用能力等基准测试评估中取得了与其他顶级模型(例如 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro)相比极具竞争力的结果。此外,小型 MoE 模型Qwen3-30B-A3B 的激活参数量是 QwQ-32B 的 10 倍,即使是像 Qwen3-4B 这样的微型模型也能与 Qwen2.5-72B-Instruct 的性能相媲美。
模型
| 名称 | 尺寸 | 上下文 | 输入 | Ollama 下载命令 |
|---|---|---|---|---|
| qwen3:latest | 5.2GB | 40K | 文本 | ollama run qwen3:latest |
| qwen3:0.6b | 523MB | 40K | 文本 | ollama run qwen3:0.6b |
| qwen3:1.7b | 1.4GB | 40K | 文本 | ollama run qwen3:1.7b |
| qwen3:4b | 2.5GB | 256K | 文本 | ollama run qwen3:4b |
| qwen3:8b | 5.2GB | 40K | 文本 | ollama run qwen3:8b |
| qwen3:14b | 9.3GB | 40K | 文本 | ollama run qwen3:14b |
| qwen3:30b | 19GB | 256K | 文本 | ollama run qwen3:30b |
| qwen3:32b | 20GB | 40K | 文本 | ollama run qwen3:32b |
| qwen3:235b | 142GB | 256K | 文本 | ollama run qwen3:235b |
| qwen3:0.6b-q4_K_M | 523MB | 40K | 文本 | ollama run qwen3:0.6b-q4_K_M |
| qwen3:0.6b-q8_0 | 832MB | 40K | 文本 | ollama run qwen3:0.6b-q8_0 |
| qwen3:0.6b-fp16 | 1.5GB | 40K | 文本 | ollama run qwen3:0.6b-fp16 |
| qwen3:1.7b-q4_K_M | 1.4GB | 40K | 文本 | ollama run qwen3:1.7b-q4_K_M |
| qwen3:1.7b-q8_0 | 2.2GB | 40K | 文本 | ollama run qwen3:1.7b-q8_0 |
| qwen3:1.7b-fp16 | 4.1GB | 40K | 文本 | ollama run qwen3:1.7b-fp16 |
| qwen3:4b-instruct | 2.5GB | 256K | 文本 | ollama run qwen3:4b-instruct |
| qwen3:4b-instruct-2507-q4_K_M | 2.5GB | 256K | 文本 | ollama run qwen3:4b-instruct-2507-q4_K_M |
| qwen3:4b-instruct-2507-q8_0 | 4.3GB | 256K | 文本 | ollama run qwen3:4b-instruct-2507-q8_0 |
| qwen3:4b-instruct-2507-fp16 | 8.1GB | 256K | 文本 | ollama run qwen3:4b-instruct-2507-fp16 |
| qwen3:4b-thinking | 2.5GB | 256K | 文本 | ollama run qwen3:4b-thinking |
| qwen3:4b-thinking-2507-q4_K_M | 2.5GB | 256K | 文本 | ollama run qwen3:4b-thinking-2507-q4_K_M |
| qwen3:4b-thinking-2507-q8_0 | 4.3GB | 256K | 文本 | ollama run qwen3:4b-thinking-2507-q8_0 |
| qwen3:4b-thinking-2507-fp16 | 8.1GB | 256K | 文本 | ollama run qwen3:4b-thinking-2507-fp16 |
| qwen3:4b-q4_K_M | 2.6GB | 40K | 文本 | ollama run qwen3:4b-q4_K_M |
| qwen3:4b-q8_0 | 4.4GB | 40K | 文本 | ollama run qwen3:4b-q8_0 |
| qwen3:4b-fp16 | 8.1GB | 40K | 文本 | ollama run qwen3:4b-fp16 |
| qwen3:8b-q4_K_M | 5.2GB | 40K | 文本 | ollama run qwen3:8b-q4_K_M |
| qwen3:8b-q8_0 | 8.9GB | 40K | 文本 | ollama run qwen3:8b-q8_0 |
| qwen3:8b-fp16 | 16GB | 40K | 文本 | ollama run qwen3:8b-fp16 |
| qwen3:14b-q4_K_M | 9.3GB | 40K | 文本 | ollama run qwen3:14b-q4_K_M |
| qwen3:14b-q8_0 | 16GB | 40K | 文本 | ollama run qwen3:14b-q8_0 |
| qwen3:14b-fp16 | 30GB | 40K | 文本 | ollama run qwen3:14b-fp16 |
| qwen3:30b-a3b | 19GB | 256K | 文本 | ollama run qwen3:30b-a3b |
| qwen3:30b-a3b-instruct-2507-q4_K_M | 19GB | 256K | 文本 | ollama run qwen3:30b-a3b-instruct-2507-q4_K_M |
| qwen3:30b-a3b-instruct-2507-q8_0 | 32GB | 256K | 文本 | ollama run qwen3:30b-a3b-instruct-2507-q8_0 |
| qwen3:30b-a3b-instruct-2507-fp16 | 61GB | 256K | 文本 | ollama run qwen3:30b-a3b-instruct-2507-fp16 |
| qwen3:30b-a3b-q4_K_M | 19GB | 40K | 文本 | ollama run qwen3:30b-a3b-q4_K_M |
| qwen3:30b-a3b-q8_0 | 33GB | 40K | 文本 | ollama run qwen3:30b-a3b-q8_0 |
| qwen3:30b-a3b-thinking-2507-q4_K_M | 19GB | 256K | 文本 | ollama run qwen3:30b-a3b-thinking-2507-q4_K_M |
| qwen3:30b-a3b-thinking-2507-q8_0 | 32GB | 256K | 文本 | ollama run qwen3:30b-a3b-thinking-2507-q8_0 |
| qwen3:30b-a3b-thinking-2507-fp16 | 61GB | 256K | 文本 | ollama run qwen3:30b-a3b-thinking-2507-fp16 |
| qwen3:30b-a3b-fp16 | 61GB | 40K | 文本 | ollama run qwen3:30b-a3b-fp16 |
| qwen3:30b-thinking | 19GB | 256K | 文本 | ollama run qwen3:30b-thinking |
| qwen3:32b-q4_K_M | 20GB | 40K | 文本 | ollama run qwen3:32b-q4_K_M |
| qwen3:32b-q8_0 | 35GB | 40K | 文本 | ollama run qwen3:32b-q8_0 |
| qwen3:32b-fp16 | 66GB | 40K | 文本 | ollama run qwen3:32b-fp16 |
| qwen3:235b-a22b | 142GB | 256K | 文本 | ollama run qwen3:235b-a22b |
| qwen3:235b-a22b-instruct-2507-q4_K_M | 142GB | 256K | 文本 | ollama run qwen3:235b-a22b-instruct-2507-q4_K_M |
| qwen3:235b-a22b-instruct-2507-q8_0 | 250GB | 256K | 文本 | ollama run qwen3:235b-a22b-instruct-2507-q8_0 |
| qwen3:235b-a22b-thinking-2507-q4_K_M | 142GB | 256K | 文本 | ollama run qwen3:235b-a22b-thinking-2507-q4_K_M |
| qwen3:235b-a22b-thinking-2507-q8_0 | 250GB | 256K | 文本 | ollama run qwen3:235b-a22b-thinking-2507-q8_0 |
| qwen3:235b-a22b-q4_K_M | 142GB | 40K | 文本 | ollama run qwen3:235b-a22b-q4_K_M |
| qwen3:235b-a22b-q8_0 | 250GB | 40K | 文本 | ollama run qwen3:235b-a22b-q8_0 |
| qwen3:235b-a22b-fp16 | 470GB | 40K | 文本 | ollama run qwen3:235b-a22b-fp16 |
| qwen3:235b-a22b-thinking-2507-fp16 | 470GB | 256K | 文本 | ollama run qwen3:235b-a22b-thinking-2507-fp16 |
| qwen3:235b-thinking | 142GB | 256K | 文本 | ollama run qwen3:235b-thinking |
全新更新了 30B 和 235B 模型
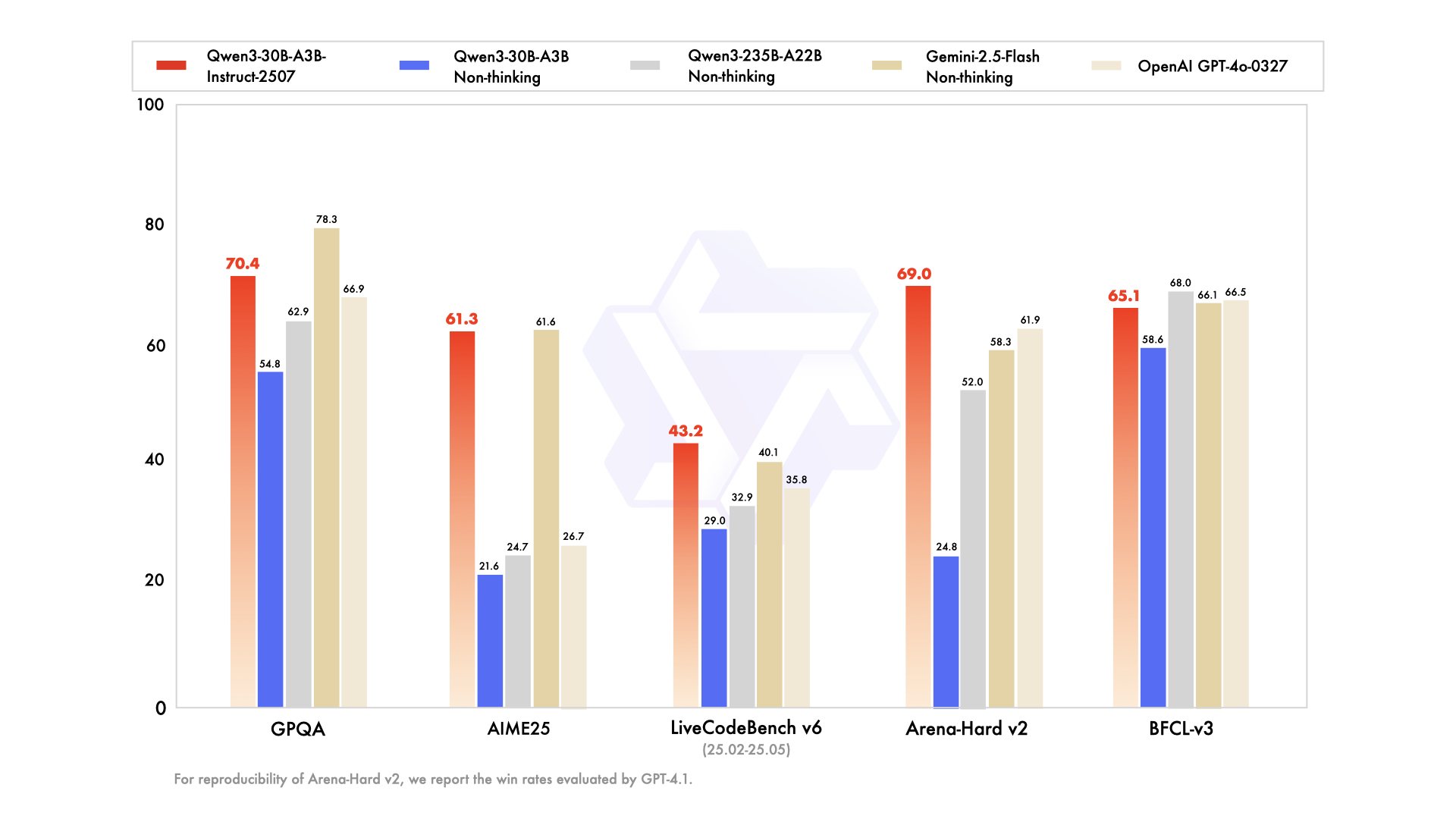
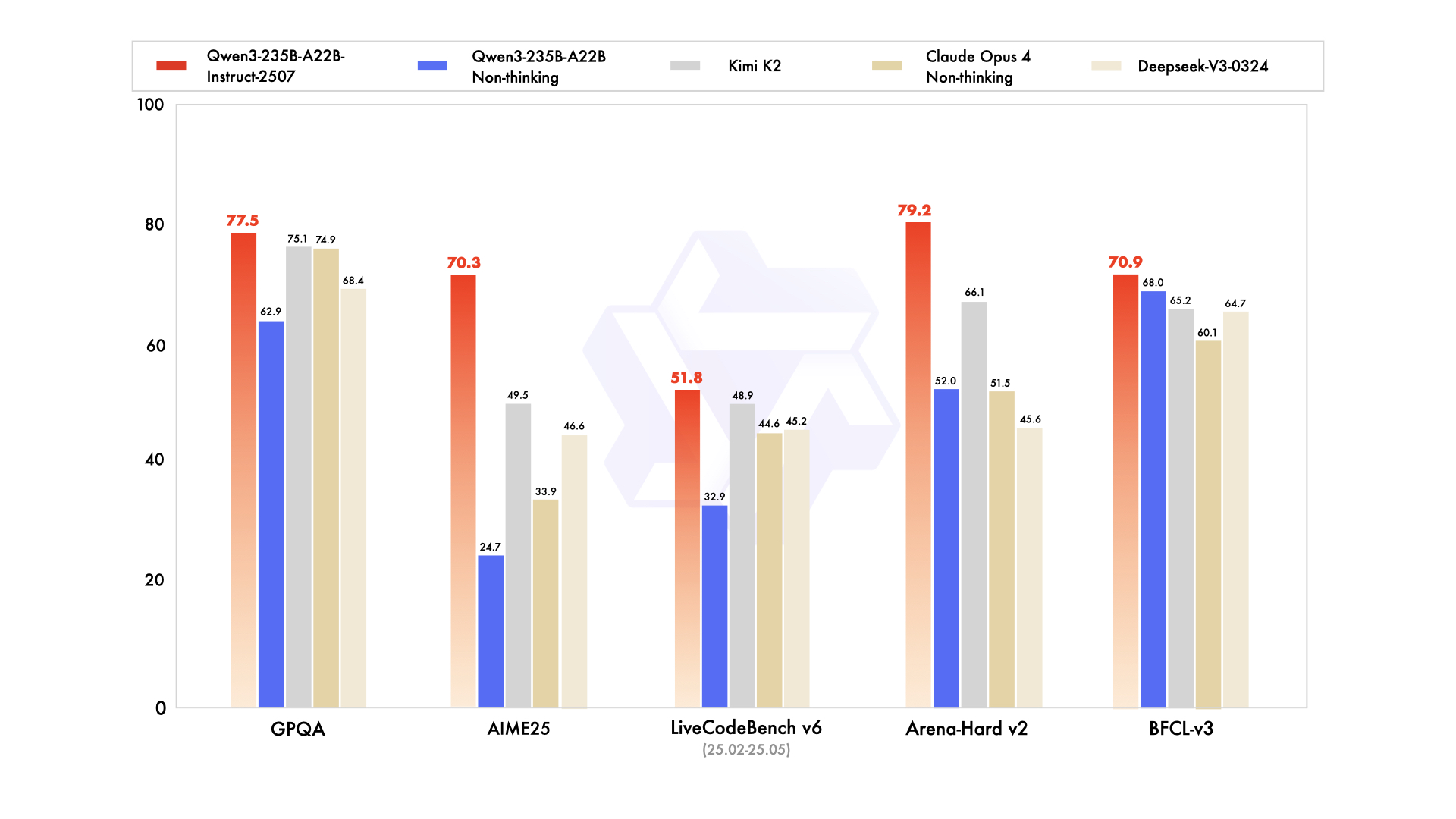
- 推理能力大幅增强,在数学、代码生成、常识逻辑推理等方面超越了之前的QwQ(思维模式)和Qwen2.5指令模型(非思维模式)。
- 卓越的人类偏好一致性,擅长创意写作、角色扮演、多轮对话和指令遵循,提供更自然、更具吸引力和身临其境的对话体验。
- 精通代理能力,能够以思考和非思考两种模式与外部工具精准集成,在基于代理的复杂任务中实现开源模型的领先性能。
- 支持 100 多种语言和方言,具有强大的多语言指令跟踪和翻译能力。