↑

概述

EmbeddingGemma是一个 3 亿参数的开源嵌入模型,在同等规模下堪称顶尖。该模型由 Google 开发,基于 Gemma 3(采用 T5Gemma 初始化)构建,并采用了与创建 Gemini 模型相同的研究和技术。EmbeddingGemma 能够生成文本的向量表示,非常适合搜索和检索任务,包括分类、聚类和语义相似性搜索。该模型已使用 100 多种口语数据进行训练。
小巧的尺寸和对设备的关注使其能够在资源有限的环境中部署,例如手机、笔记本电脑或台式机,从而实现对最先进的人工智能模型的民主化访问,并帮助促进每个人的创新。
基准
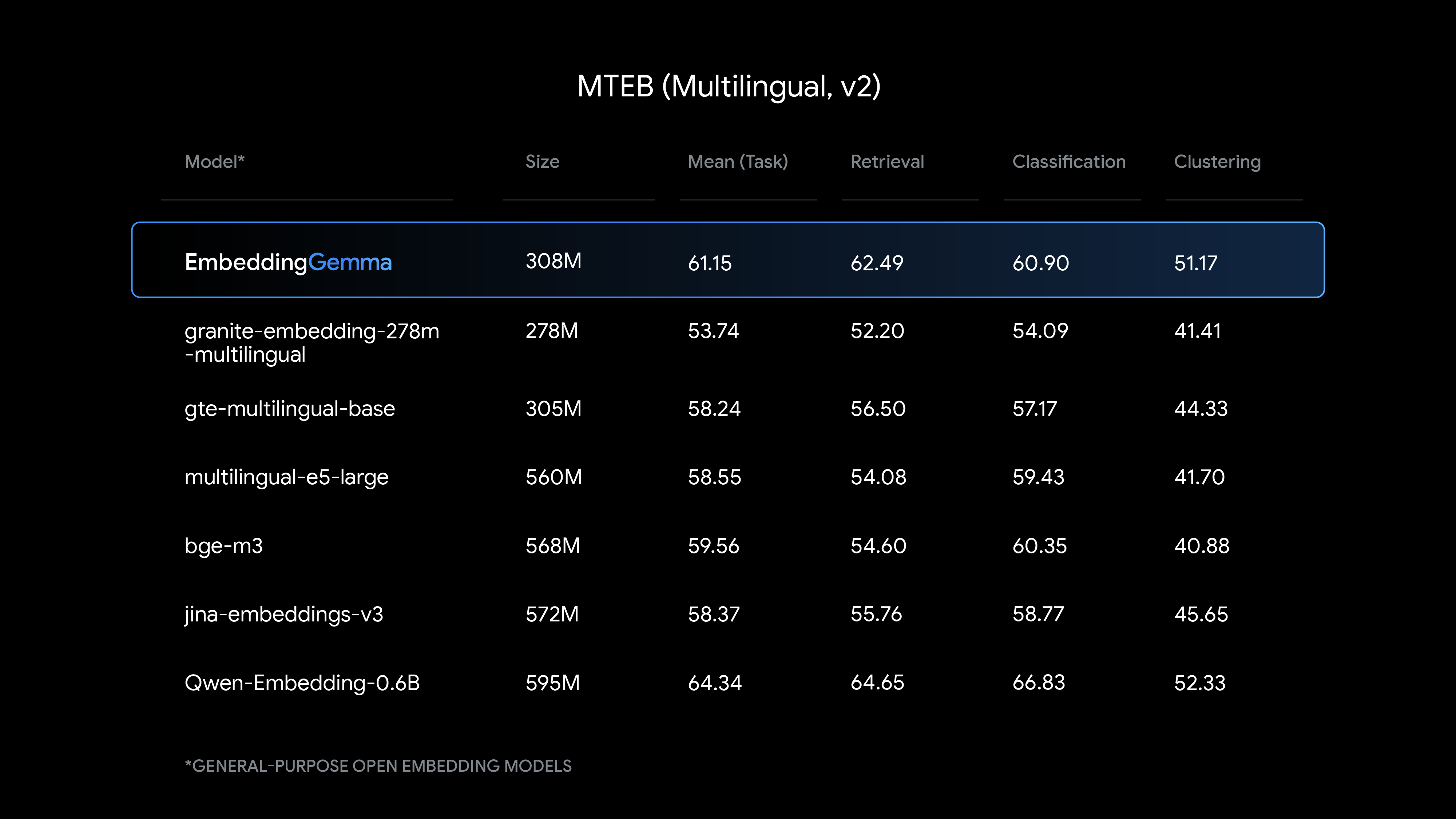
训练数据集
该模型基于一个文本数据集进行训练,该数据集包含各种来源,总计约 3200 亿个标记。以下是其关键组成部分:
- **网络文档:**丰富的网络文本集合确保模型能够接触到广泛的语言风格、主题和词汇。训练数据集包含超过 100 种语言的内容。
- **代码和技术文档:**将模型暴露于代码和技术文档有助于它学习编程语言和专业科学内容的结构和模式,从而提高它对代码和技术问题的理解。
- **合成数据和特定任务数据:**合成训练数据有助于教授模型特定技能。这包括针对信息检索、分类和情感分析等任务的精选数据,有助于微调其在常见嵌入应用中的性能。
这些不同数据源的组合对于训练能够处理各种不同任务和数据格式的强大的多语言嵌入模型至关重要。