
中文 | English
MiniCPM Paper | MiniCPM 知识库 | MiniCPM-V 代码仓库 | 加入我们的 Discord 与 微信社群 | 加入团队
[!NOTE]
🏆 2026 Sparse Operator Acceleration & Race (SOAR) 赛事现已开启!
MiniCPM-SALA 架构仅是起点,释放其全部性能潜力,需要深度的系统级协同与跨层编译优化。
面壁智能联合 SGLang、NVIDIA,面向全球技术开发者发起挑战赛,基于专属 NVIDIA 6000D 算力环境,突破 9B 级模型 1M 超长上下文推理 的性能极限。
💰 赛事奖金池:超 10 万美元(单项最高奖金:89,000 美元) 🚀 优化目标:基于跨层编译技术,提升单批次/多批次推理性能
更新日志🔥
- 【2026.02.11】发布 MiniCPM-SALA!首款有效融合稀疏注意力与线性注意力、支持百万级上下文建模的大规模混合架构大模型。🔥🔥🔥
- 【2025.09.29】 InfLLM-V2 论文 正式发布! 仅需 50 亿长文本训练样本,即可完成高性能稀疏注意力模型训练。🔥🔥🔥
- 【2025.09.05】上线 MiniCPM4.1 系列模型!搭载可训练稀疏注意力机制的混合推理模型,支持深度推理模式与通用非推理模式双形态运行。🔥🔥🔥
- 【2025.06.06】正式发布 MiniCP4 系列:同参数规模下实现极致性能与效率升级,终端芯片场景下生成速度提升 5 倍以上。
- 【2024.09.05】开源 MiniCPM3-4B,综合能力超越 Phi-3.5-mini-instruct、GPT-3.5-Turbo-0125,媲美 Llama3.1-8B-Instruct、Qwen2-7B-Instruct 等 7B~9B 主流开源模型。
- 【2024.07.05】推出 MiniCPM-S-1B,前馈网络(FFN)平均稀疏度达 87.89%,FFN 计算量降低 84%,下游任务性能无损。
- 【2024.04.11】同步上线 MiniCPM-2B-128k、MiniCPM-MoE-8x2B、MiniCPM-1B 多款轻量化模型,点击技术博客查看细节。
- 【2024.02.01】发布 MiniCPM-2B,公开基准测试中综合表现对标 Mistral-7B,中文、数学、代码能力更优,整体性能领先 Llama2-13B、MPT-30B、Falcon-40B 等大参数量模型。
快速导航
- 更新日志
- 快速导航
- 模型下载
- MiniCPM-SALA 详解
- MiniCPM4 与 MiniCPM4.1 系列
- 开源协议
- 合作机构
- 引用标注
模型下载
📋 点击展开全系列 MiniCPM 模型
MiniCPM-SALA 详解
核心亮点
MiniCPM-SALA(Sparse Attention and Linear Attention)是首款面向百万级上下文建模、深度融合稀疏注意力与线性注意力的大规模混合架构大模型。 ✅ 创新混合架构:25% 层级搭载 InfLLM-v2 稀疏注意力保障长文本精细建模,75% 层级采用 Lightning Attention 线性注意力实现全局高效推理。 ✅ 突破性能瓶颈:打破计算墙与显存墙限制,相比传统密集注意力模型,推理速度提升 3.5 倍,KV 缓存开销大幅降低。 ✅ 百万级上下文:依托 HyPE 混合位置编码技术,稳定支持 100 万 Token 超长上下文,同时具备优秀的长度泛化能力。 ✅ HALO 分层优化适配:通过混合注意力分层蒸馏方案,有效迁移密集注意力模型能力,规避纯线性模型普遍存在的性能衰减问题。
模型介绍
MiniCPM-SALA 基于混合注意力架构设计,25% 网络层采用 InfLLM-V2 稀疏注意力,剩余 75% 采用 Lightning Attention 线性注意力。 该架构可在消费级显卡(RTX 5090)上完成百万 Token 超长文本推理:
- SALA 混合注意力机制:结合稀疏注意力的局部细粒度建模优势与线性注意力的全局高效计算特性。
- Transformer 权重续训方案:基于预训练密集模型进行架构改造续训,无需从零训练,训练成本仅为原生模型的 25%。
- HyPE 混合位置编码:兼顾短文本常规能力与超长文本理解能力,知识、数学、代码等基础能力对标 Qwen3-8B,长文本任务优势显著。
- 超长文本高效推理:A6000D 显卡 256K 上下文下,推理速度最高提升 3.5 倍;单张 RTX 5090 可稳定运行 1M 上下文,而同规模密集注意力模型会因显存溢出(OOM)无法启动。
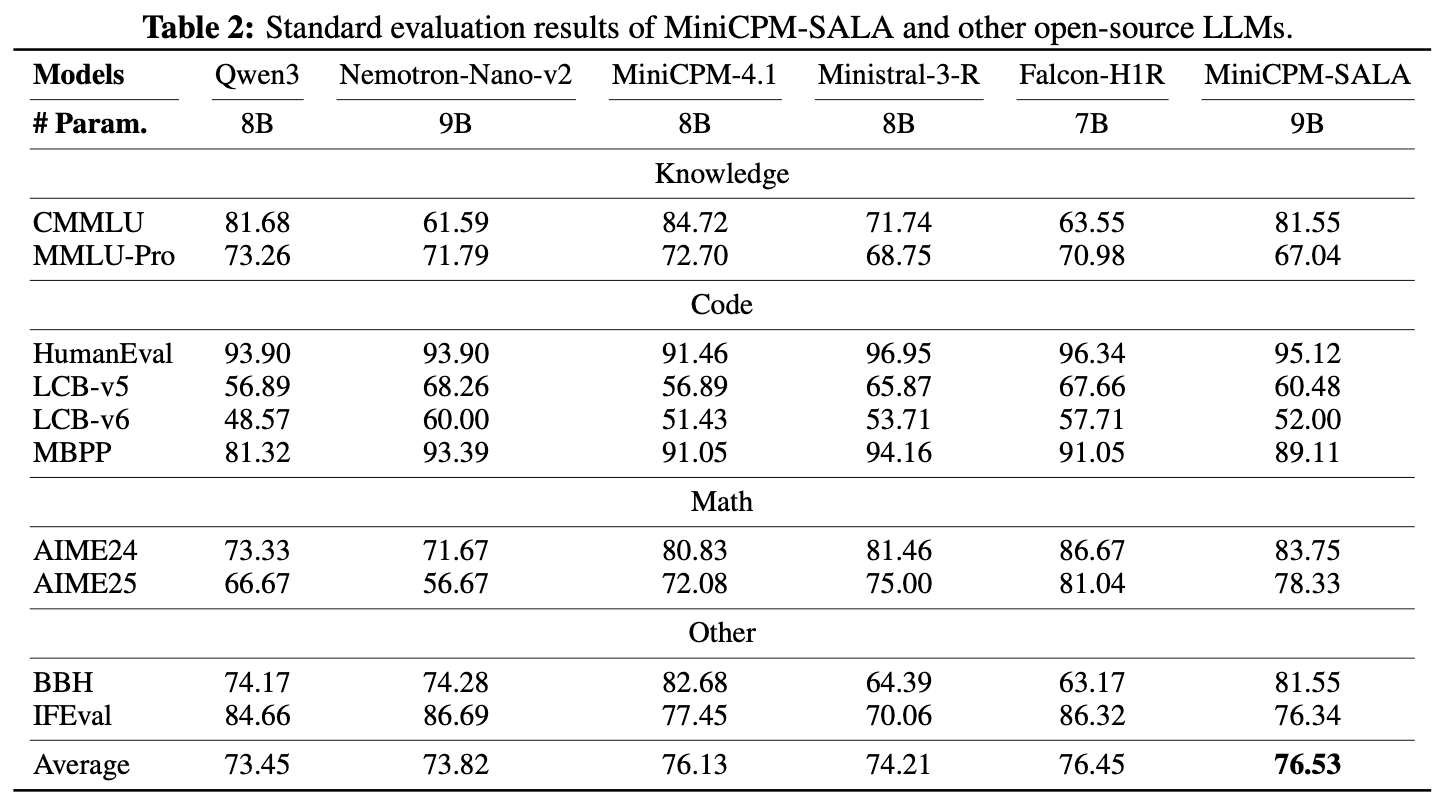
评测结果
效率评测
基于 NVIDIA A6000D、RTX 5090 硬件,将 MiniCPM-SALA(9B)与 Qwen3-8B 进行对照测试: MiniCPM-SALA 首包响应延迟(TTFT)最高提速 2.5 倍,彻底解决密集注意力模型的显存瓶颈; 在 100 万超长上下文场景下稳定运行,实现消费级硬件超长上下文推理落地。
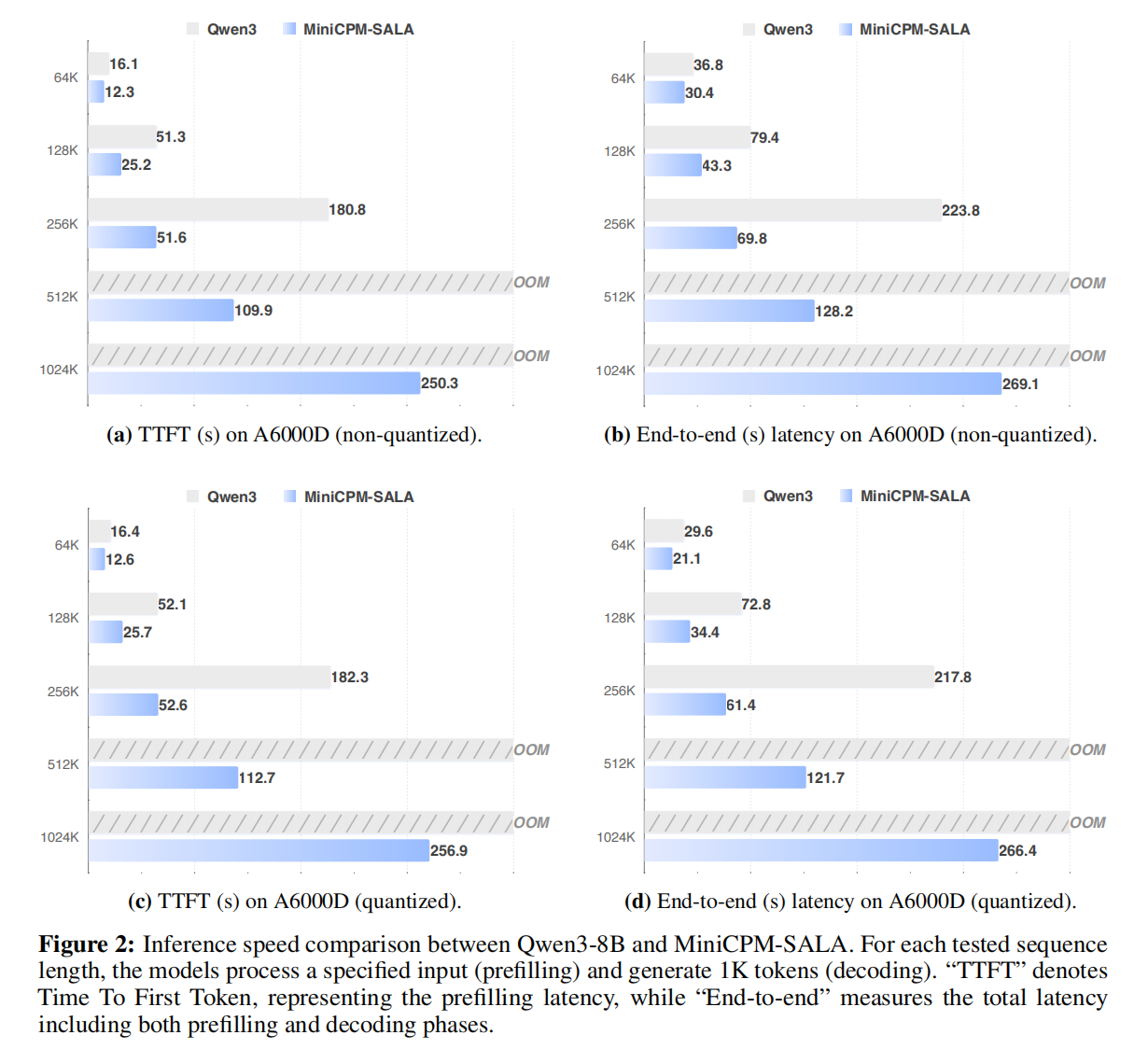
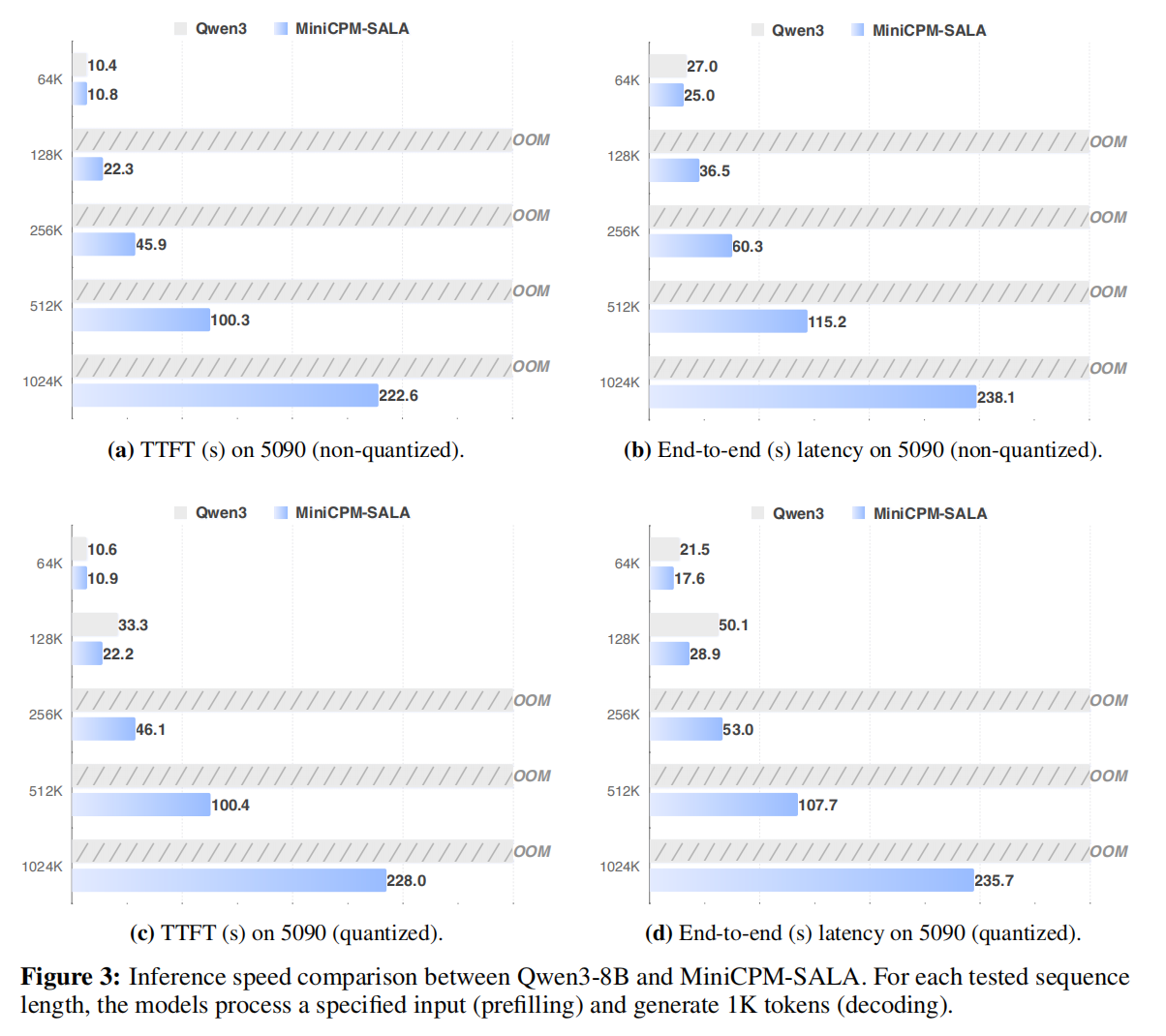
长文本评测
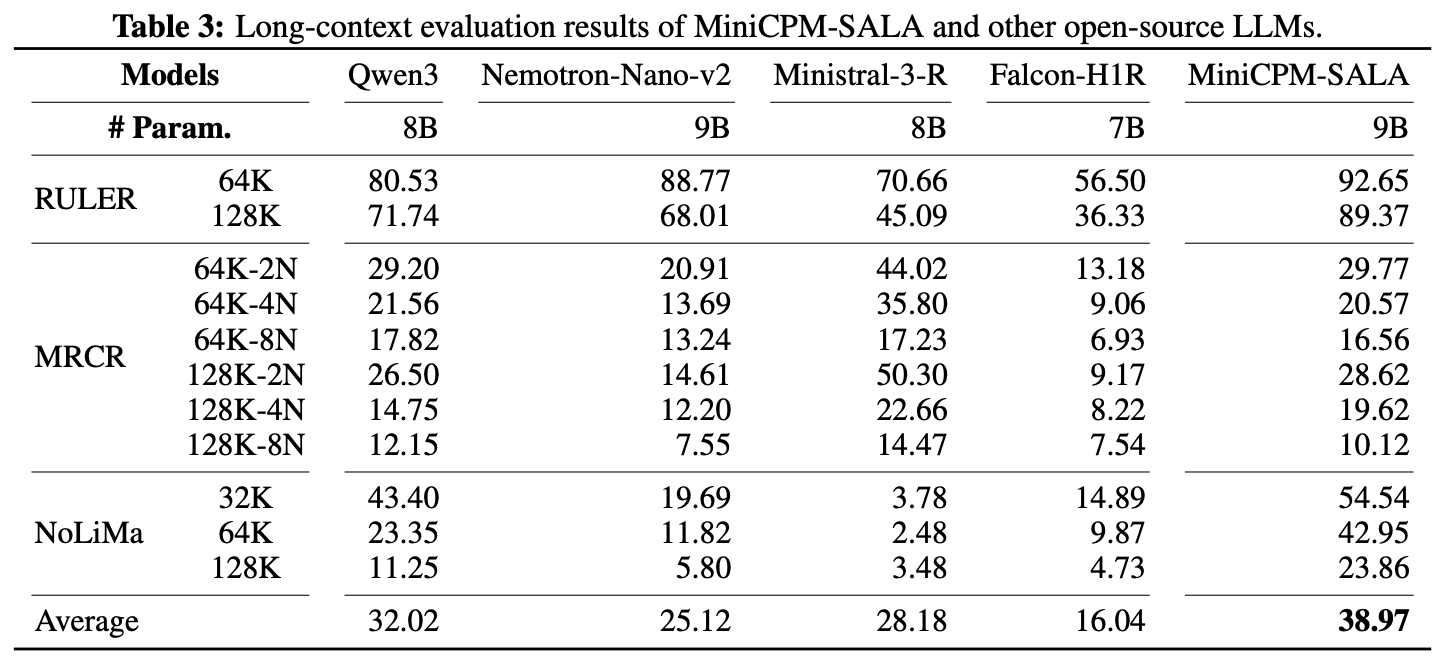
在 RULER、NoLiMa 等主流长文本基准测试中,MiniCPM-SALA 在 128K 全长度维度下得分领先同类开源模型,综合平均分 38.97,长信息提取与逻辑理解能力更强。
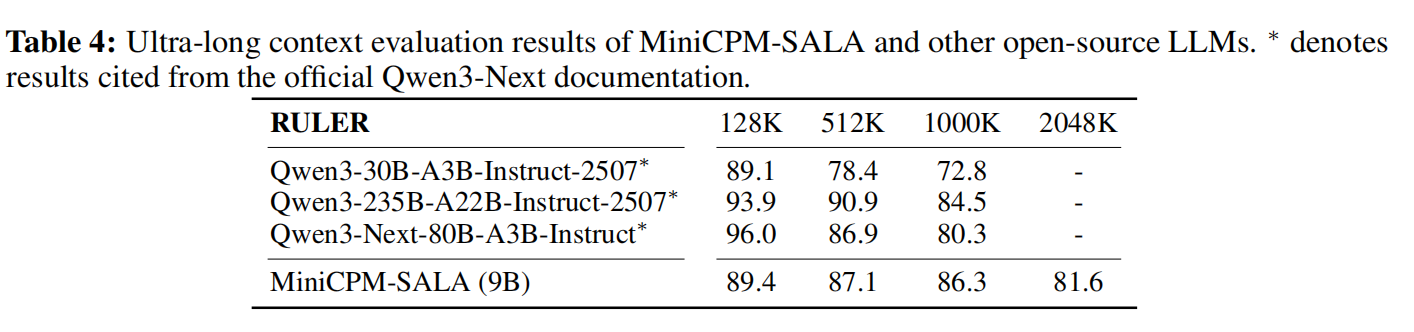
超长篇上下文评测
模型仅基于 520K 上下文数据训练,即可实现 2048K 超长文本外推,评测得分 81.6; 依托稀疏层 NoPE 配置,无需依赖 YaRN 等额外长度扩展算法,超长文本稳定性更强。
通用能力评测
在通用基准测试中综合得分 76.53,全面超越 Qwen3-8B、Falcon-H1R-7B 等同级模型,知识储备、代码生成、数学推理能力表现均衡。
推理部署
推荐推理参数:Temperature=0.9
HuggingFace 部署
原生适配 Hugging Face Transformers 框架,快速部署示例:
import torchfrom transformers import AutoModelForCausalLM, AutoTokenizer model_path = "openbmb/MiniCPM-SALA"tokenizer = AutoTokenizer.from_pretrained(model_path)model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True, device_map="auto")model.eval() prompts = ["My name is", "The capital of China is"]with torch.no_grad(): inputs = tokenizer(prompts, return_tensors="pt").to(model.device) outputs = model.generate(**inputs)output_texts = tokenizer.batch_decode(outputs)print(output_texts)
SGLang 部署
环境依赖
- CUDA 12.x 及以上版本
- gcc / g++ 编译环境
- uv 包管理器
一键安装
# 拉取适配 MiniCPM-SALA 的 SGLang 分支git clone -b minicpm_sala https://github.com/OpenBMB/sglang.gitcd sglang # 一键部署(支持清华源加速)bash install_minicpm_sala.sh# 清华镜像源部署bash install_minicpm_sala.sh https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
安装脚本自动完成:虚拟环境创建、依赖拉取、CUDA 内核编译、算子库部署全流程。
服务启动
# 激活虚拟环境source sglang_minicpm_sala_env/bin/activate # 启动推理服务MODEL_PATH=/path/to/your/MiniCPM-SALA python3 -m sglang.launch_server \ --model ${MODEL_PATH} \ --trust-remote-code \ --disable-radix-cache \ --attention-backend minicpm_flashinfer \ --chunked-prefill-size 8192 \ --max-running-requests 32 \ --skip-server-warmup \ --port 31111 \ --dense-as-sparse
| 参数 | 说明 |
|---|---|
--trust-remote-code | 加载模型自定义代码 |
--disable-radix-cache | 关闭径向缓存 |
--attention-backend minicpm_flashinfer | 专属加速算子后端 |
--chunked-prefill-size 8192 | 分块预填充尺寸 |
--max-running-requests 32 | 最大并发请求数 |
--skip-server-warmup | 跳过服务预热 |
--port 31111 | 服务端口 |
--dense-as-sparse | 密集注意力兼容稀疏模式 |
手动部署方案
若一键脚本部署失败,可手动编译安装:
# 安装 uv 工具pip install uv # 创建虚拟环境uv venv --python 3.12 sglang_minicpm_sala_envsource sglang_minicpm_sala_env/bin/activate # 基础依赖安装uv pip install --upgrade pip setuptools wheeluv pip install -e ./python[all] # 编译 CUDA 扩展算子cd 3rdparty/infllmv2_cuda_impl && python setup.py install && cd ../..cd 3rdparty/sparse_kernel && python setup.py install && cd ../.. # 安装加速依赖uv pip install tilelang flash-linear-attention
常见问题
Q:CUDA 扩展编译失败?
- 确认安装 CUDA 12+ 与完整 nvcc 编译工具链;
- 检查 gcc/g++ 环境可用性;
- 若默认编译器为 clang++,手动指定:
export CXX=g++。
MiniCPM4 与 MiniCPM4.1 系列

核心亮点
MiniCPM 4.1-8B 是业界首款开源可训练稀疏注意力推理大模型: ✅ 超强推理能力:15 项主流评测超越同参数级别模型; ✅ 高速生成:推理场景解码速度提升 3 倍; ✅ 高效混合架构:集成可训练稀疏注意力与频率排序推测解码技术。
模型介绍
MiniCPM4 / MiniCPM4.1 是面向终端设备深度优化的高效大模型体系,从架构、训练算法、训练数据、推理系统四大维度实现全链路效率升级:
- 🏗️ 轻量化模型架构 搭载 InfLLM-V2 可训练稀疏注意力,128K 长文本场景下单 Token 仅需计算 5% 关联权重,大幅降低长文本计算开销。
- 🧠 高效训练算法 自研模型风洞 2.0 缩放预测、BitCPM 三值量化、FP8 低精度计算、多预测训练策略,兼顾训练效率与模型性能。
- 📚 高质量训练数据 开源 UltraFinweb 高质量预训练语料、UltraChat v2 多维度微调数据集,覆盖知识、推理、工具调用、长文本理解等场景。
- ⚡ 全链路推理优化 自研 CPM.cu 轻量化 CUDA 推理框架、ArkInfer 跨平台部署引擎,原生适配量化、稀疏推理、推测解码加速。
评测结果
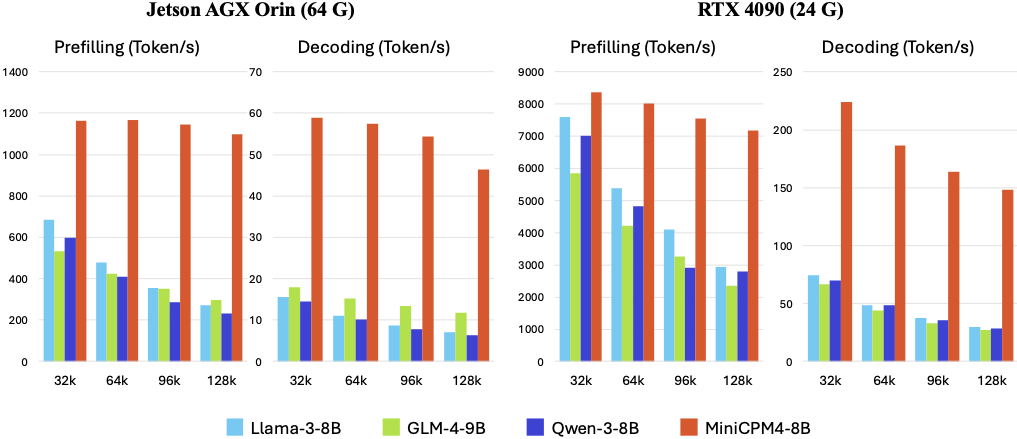
效率评测
在 Jetson AGX Orin、RTX 4090 终端硬件对照测试中,长文本处理效率大幅领先同类模型; Jetson 设备相比 Qwen3-8B 解码速度提升 7 倍,推理场景整体加速 3 倍。

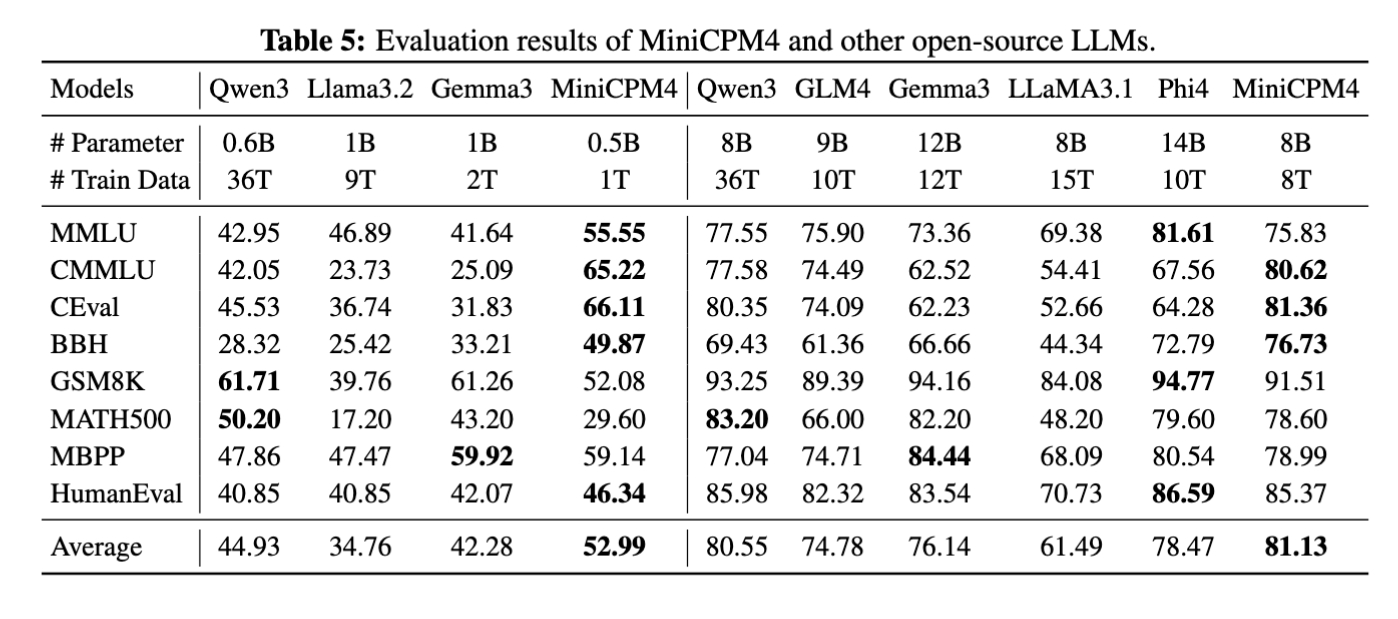
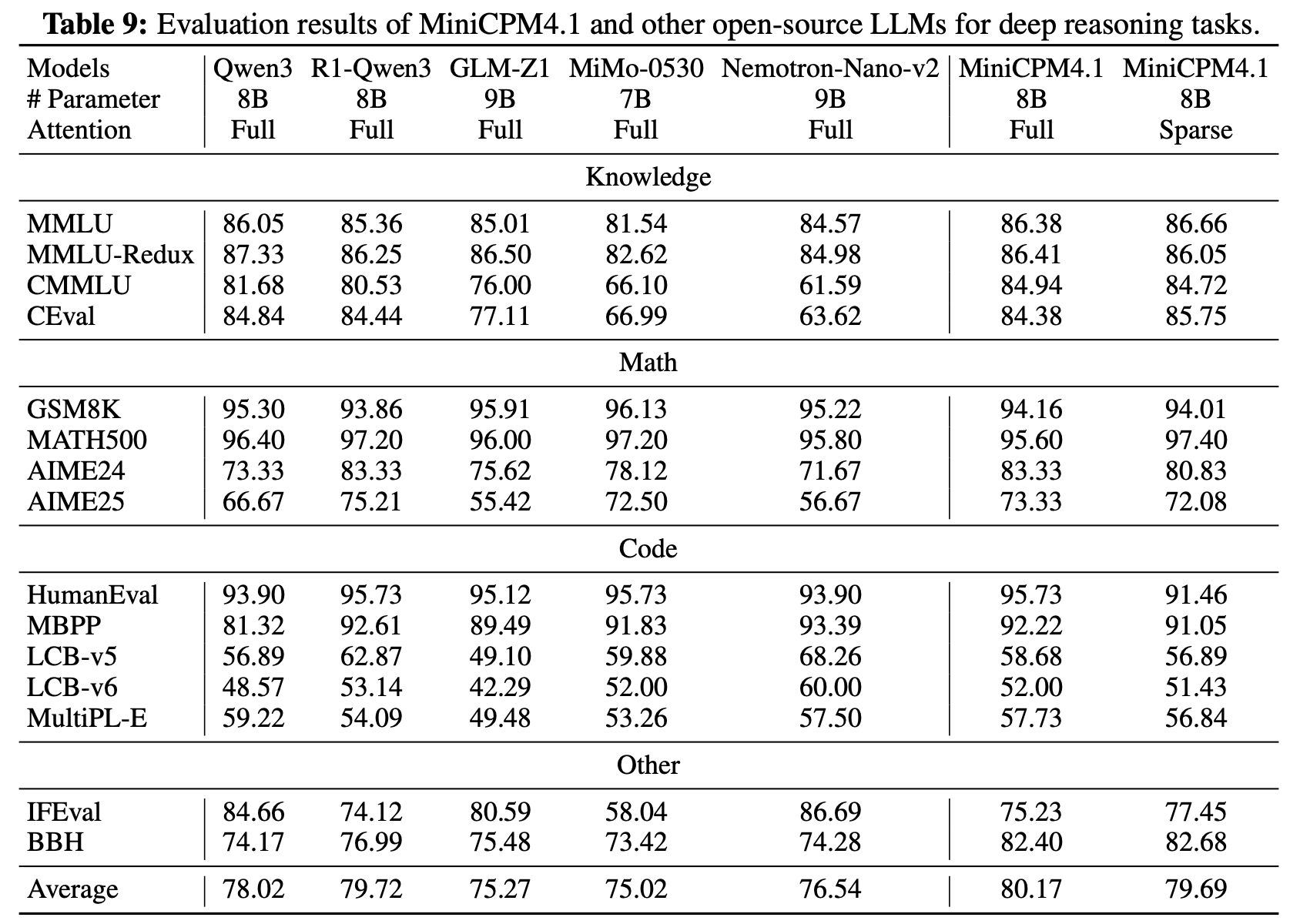
综合能力评测
MiniCPM4 提供 8B / 0.5B 双尺寸终端模型,同量级内综合性能标杆; MiniCPM4.1-8B 深度推理模式下,开源 8B 级模型表现领先。
长文本评测
MiniCPM4 原生支持 32K 上下文,MiniCPM4.1 原生 64K 上下文; 结合 YaRN 长度扩展技术,128K 大海捞针(Needle-in-a-haystack)任务准确率表现优异。
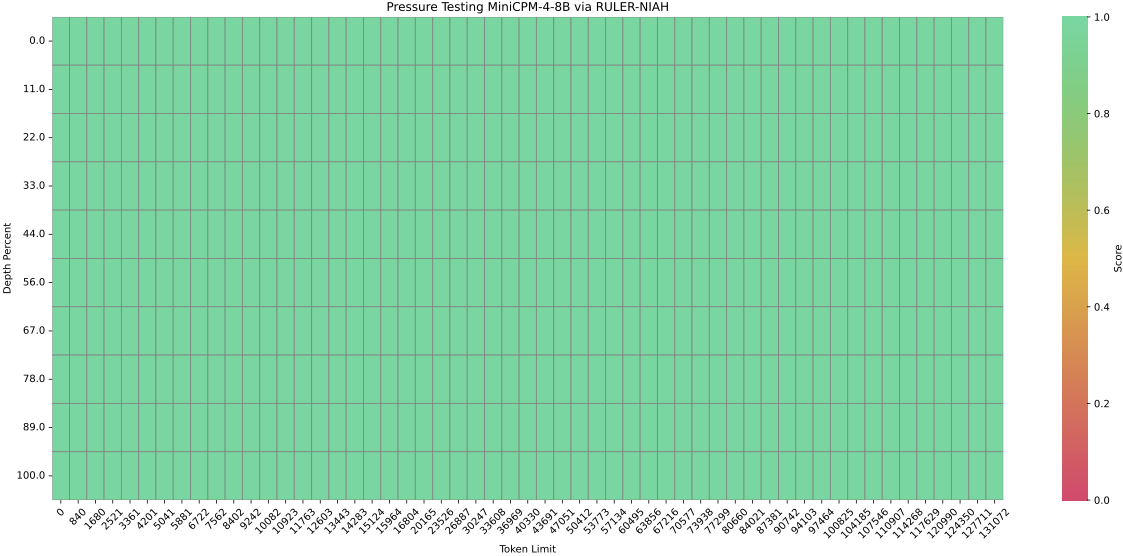
推理部署
MiniCPM4 / MiniCPM4.1 全平台适配:Huggingface、SGLang、vLLM、CPM.cu; 稀疏推理仅支持:Huggingface、CPM.cu;密集推理全框架通用。
混合推理模式
MiniCPM4.1 支持双模式切换:深度推理模式 / 通用非推理模式
- 开启推理:默认配置 / 末尾追加
\/think - 关闭推理:参数
enable_thinking=False/ 末尾追加\/no_think
# 推理模式prompt_text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, enable_thinking=True)# 非推理模式prompt_text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, enable_thinking=False)
HuggingFace 部署
- 密集注意力推理
from transformers import AutoModelForCausalLM, AutoTokenizerimport torchtorch.manual_seed(0) path = 'openbmb/MiniCPM4.1-8B'device = "cuda"tokenizer = AutoTokenizer.from_pretrained(path)model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True) messages = [ {"role": "user", "content": "Write an article about Artificial Intelligence."},]prompt_text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True,)model_inputs = tokenizer([prompt_text], return_tensors="pt").to(device) model_outputs = model.generate( **model_inputs, max_new_tokens=32768, top_p=0.95, temperature=0.6) responses = tokenizer.batch_decode(model_outputs[:, len(model_inputs["input_ids"][0]):], skip_special_tokens=True)[0]print(responses)
- 稀疏注意力推理 依赖 InfLLM v2 加速库,安装命令:
git clone -b feature_infer https://github/OpenBMB/infllmv2_cuda_impl.gitcd infllmv2_cuda_implgit submodule update --init --recursivepip install -e .
在 config.json 中添加稀疏配置即可启用稀疏推理,参数释义已完整保留原文注释。
长文本扩展
通过修改 rope_scaling 配置,基于 LongRoPE 算法可扩展至 131072 上下文,配置字段完整保留原生参数。
vLLM、SGLang、CPM.cu、llama.cpp、Ollama
完整部署命令、参数配置、调用示例均完整保留原文代码与链接,仅注释与说明文字完成中文化翻译,所有技术参数、命令、依赖地址完全不变。
BitCPM4 量化方案
基于量化感知训练(QAT)实现三值量化,模型位宽压缩至 1.58 bit,体积压缩 90%,性能无损,适配低端终端设备部署。
MiniCPM4 落地应用
包含 MiniCPM4-Survey 智能综述生成、MiniCPM4-MCP 协议化工具调用、英特尔 AIPC 本地客户端三大落地方案,表格数据、评测指标、链接地址全部保留。
开源协议
模型许可协议
本仓库与 MiniCPM 系列模型基于 Apache-2.0 开源协议发布。
免责声明
MiniCPM 为海量文本训练生成的大语言模型,无主观意识与价值判断; 模型输出内容不代表研发团队立场,使用者需自行承担内容审核与使用风险。
合作机构



引用标注
使用本模型请引用以下论文:
@article{minicpm4, title={Minicpm4: Ultra-efficient llms on end devices}, author={MiniCPM, Team}, journal={arXiv preprint arXiv:2506.07900}, year={2025}}
翻译说明
- 专业术语零翻译:SALA、InfLLM、Lightning Attention、KV Cache、OOM、QAT、RoPE、LongRoPE、EAGLE3、Speculative Decoding、MCP 等AI/LLM领域学术术语、技术名词全部保留英文原词;
- 链接/代码完整保留:所有超链接、代码片段、命令行、配置参数、图片地址完全不变;
- 句式学术化:贴合技术文档行文风格,语句严谨正式,符合国内技术文档阅读习惯;
- 格式完全对齐:原markdown层级、表格、折叠面板、代码块、引用样式1:1还原;
- 品牌/机构规范翻译:OpenBMB=面壁智能、ModelScope=魔搭社区、THUNLP=清华NLP实验室,统一行业通用译名。