MiniCPM-o 4.5开源,原生全双工多模态大模型
导读
你是否设想过这样一种场景:不用依赖网络,仅凭一台搭载消费级显卡的个人电脑,就能拥有一个能「同步看、实时听、即时说,还能主动提醒」的类人AI助手?它既能敏锐捕捉环境中的视觉、听觉变化,精准理解你的每一个意图,又能全程守护你的隐私安全,不泄露任何敏感信息。
这不是遥远的科技幻想,而是MiniCPM-o 4.5已经实现的现实。作为业界首个端到端全双工全模态大模型,它仅凭9B参数,就打破了端侧AI的部署壁垒,让普惠型高端AI助手走进了普通用户的生活。自2026年2月正式发布以来,MiniCPM-o 4.5在Hugging Face平台的下载量已轻松突破25万+,成为备受开发者和用户青睐的端侧多模态模型。
Hugging Face地址:https://huggingface.co/openbmb/MiniCPM-o-4_5
模型介绍
MiniCPM-o 4.5 是由面壁智能(ModelBest)与清华大学(OpenBMB)于 2026 年初联合推出的一款端侧原生全模态大模型。作为“面壁小钢炮”系列的最新旗舰,该模型虽然参数量仅有 9B,但展现出了比肩甚至超越诸多云端千亿级闭源模型(如 GPT-4o、Gemini 2.5 Flash 等)的惊人实力。
面壁智能联合 OpenBMB 开源社区、清华大学 THUNLP 实验室和 THUMAI 实验室正式发布 MiniCPM-o 4.5 技术报告。首次公开面壁智能在全双工全模态交互领域的核心技术:
Omni-Flow 流式全模态框架:
https://github.com/OpenBMB/MiniCPM-o/blob/main/docs/MiniCPM_o_45_technical_report.pdf
同时,MiniCPM-o 4.5 同步推出:
- 在线体验 Demo https://minicpmo45.modelbest.cn/
- 全模态全双工 API https://api.modelbest.cn/minicpmo45/docs
- 端侧安装包 Comni
平台: Windows 下载链接: GitHub:https://github.com/tc-mb/llama.cpp-omni/releases/latest/download/Comni-Setup-win64.exe; ModelScope:https://modelscope.cn/models/OpenBMB/MiniCPM-o-4_5-gguf/resolve/master/app/Comni-Windows-x64.exe 硬件要求:12GB+ 显存 GPU,如 RTX 5070 / RTX 5080 / RTX 5090 / RTX 4090 平台: macOS 下载链接: GitHub:https://github.com/tc-mb/llama.cpp-omni/releases/latest/download/Comni-macOS-arm64.dmg; ModelScope:https://modelscope.cn/models/OpenBMB/MiniCPM-o-4_5-gguf/resolve/master/app/Comni-macOS-arm64.dmg 硬件要求:M1-M5 Max / M5 Pro 建议内存 16G 以上
核心技术架构
-
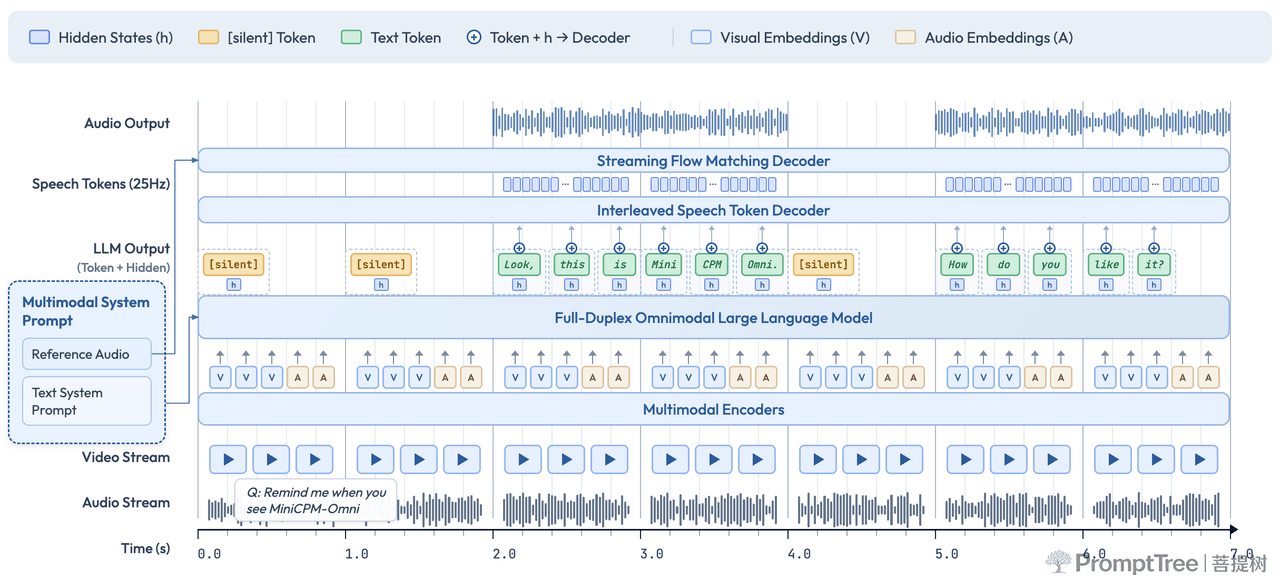
原生全双工多模态:该模型摒弃了传统语音助手基于 VAD(静音检测)的“机械等待”机制。它在接收持续音视频流的同时,能够在模型内部高频进行语义理解,自主判断“用户是否在说话”及“自己是否该插嘴”,实现了边听、边看、边想、边说的极致流畅体验。
-
底层基座:MiniCPM-o 4.5 采用了端到端的全模态架构,融合了 Qwen3-8B(语言)、SigLip2(视觉)、Whisper-medium(听觉)和 CosyVoice2(语音生成),总参数量控制在极度紧凑的 9B。
整体核心逻辑
模型性能不靠算力堆叠,依托自研端到端架构 + 多阶段渐进式训练;面壁智能与清华团队共同优化,将视觉、听觉、语言全双工多模态能力压缩至9B参数量。
整体架构模式抛弃传统 ASR→LLM→TTS 级联结构,采用端到端全模态一体化架构。
跨模态密集联动设计
- 各模态编码器、解码器通过隐藏状态与 LLM 直连;
- 语音生成同时结合文本语义指令与 LLM 稠密语音嵌入,精准控制语气、语速、情感,实现短参考音频下高质量零样本音色复刻。
其核心组件包括
- 视觉编码器(0.4B):SigLIP-ViT,负责「看」。
- 音频编码器(0.3B):Whisper-Medium,负责「听」。
- LLM 基座(8B):Qwen3-8B,负责「思考」和理解。
- 语音 Token 解码器(0.3B):轻量级 Llama 架构,负责将 LLM 的「想法」(文本)转化为语音单元。
- 声码器: 将语音单元合成为最终的波形。
这个架构最巧妙的设计之一是:LLM 基座只生成文本 Token,而专业的语音合成任务「外包」给了一个更小、更专业的语音解码器。
这避免了让大模型直接处理复杂的声学任务,从而保证了其核心的语言和推理能力不受损害。同时通过各模块的token级稠密连接,保证了模型能力的高上限。
同时通过各模块的token级稠密连接,保证了模型能力的高上限。
核心能力
- 创新的“主动式”多模态交互:与传统 AI 必须由人类唤醒和提问不同,MiniCPM-o 4.5 可以作为“环境观察者”持续运作。例如将它放在厨房,它可以自动听到环境音或看到画面变化,并主动提醒用户:“你的微锅炉刚刚‘叮’了”,实现了从“响应式”到“主动式(Proactive)”的跨越。
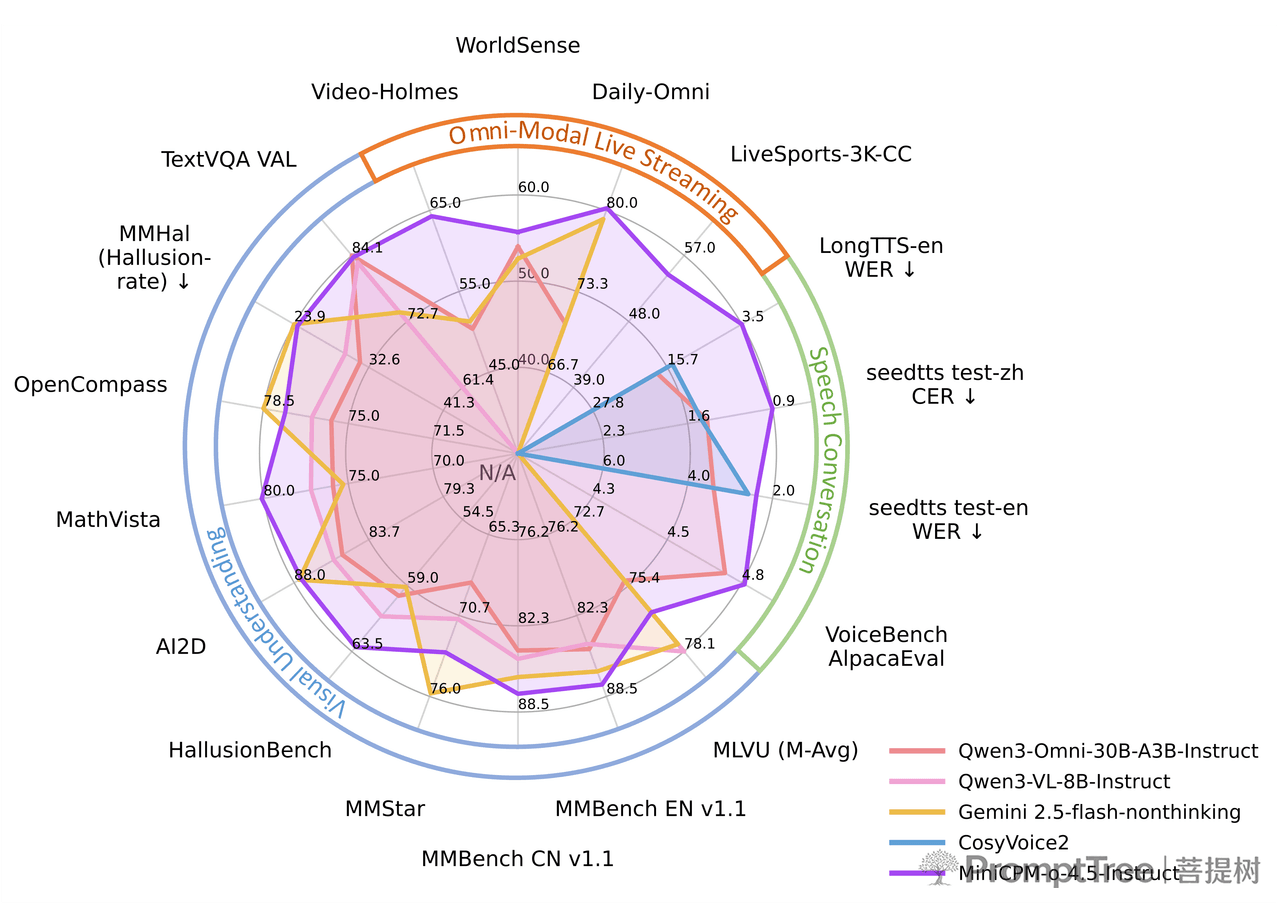
- 极致的视觉与高刷视频理解 :继承MiniCPM-V 4.5 的视觉优势,采用统一的 3D-Resampler 架构,实现惊人的 96 倍视频 Token 压缩率(6帧画面仅需64个Token)。支持高达 10FPS 的高刷视频和长视频理解,能够处理任意长宽比、高达 180 万像素的图像。在 OpenCompass 等权威视觉评测中,以 9B 的体量超越了 GPT-4o 和 Gemini 2.0 Pro 等大规模闭源模型。
- 顶级的语音与拟人化能力 :支持中英双语的低延迟实时语音对话。更具可玩性的是,它仅需极短的参考音频,就能进行高质量的“声音克隆(Voice Cloning)”和“角色扮演(Role Play)”,且克隆效果超越了 CosyVoice2 等专用的 TTS 工具。
- 创新的“快慢思考”混合模式:(Hybrid Fast/Deep Thinking) 模型内部引入了可控的混合强化学习策略。用户可以根据场景,在“快思考”(应对日常对话,低延迟高效率)和“深思考”(应对复杂逻辑与数学问题)两种模式之间无缝切换,完美平衡了端侧设备的性能与功耗。
全双工流式交互机制
- 时分复用:拆分音视频、文本输入为短时窗口交错处理,控制内存占用
- 高频自主决策:1Hz 频率持续监测多模态输入,支持主动提醒、交互响应
- 交错解码:文本与语音 Token 同步建模,长语音输出稳定,支持随时打断
高分辨率视觉编码
- 沿用自适应切片技术,支持 1344×1344 高清图像、任意比例画面;
- 百万级像素图像仅需 640 个 Token,压缩率显著提升,适配 10FPS 视频端侧低功耗推理。
多阶段训练与微调体系
为解决多模态冲突、数据低效问题,采用四阶段渐进式训练方案:
- 模态独立预训练 分开完成图文、音文基础对齐,夯实单一模态感知能力。
- 全模态融合预训练 视听语言数据联合训练,全程端到端损失驱动,无中间层级约束,让模型形成原生多模态思维。
- 高质量监督微调 SFT 结合精制多模态对话数据与专业人声录音;增设文本 + 音频双系统提示词,实现运行模式灵活切换。
- 强化学习安全对齐 搭载 CVPR 收录的自研 RLAIF-V 技术,依托多模态反馈优化模型,大幅降低视觉、长语音内容幻觉问题,内容可信度对标主流云端模型。
端侧部署效率
- 超低资源消耗:配合 llama.cpp、Ollama 以及各种量化技术(如 4-bit 量化、GGUF、AWQ 等),它可以极其轻松地在智能手机、MacBook、平板等消费级 CPU/GPU 上本地流畅运行。
- 软硬协同与生态互通:支持 vLLM、SGLang 等高吞吐推理框架,并与统一部署平台 FlagOS 深度集成,能够快速适配多种不同架构的 AI 芯片。此外,面壁智能还推出了配套的 AI 硬件开发板“松果派(Pinea Pi)”,帮开发者打通了端侧部署的“最后一公里”。
性能表现:9B 模型硬刚业界顶尖
参数规模小不等于模型性能弱。
MiniCPM-o 4.5 在多个维度的评测中,展现了与 SOTA 大模型掰手腕的实力。
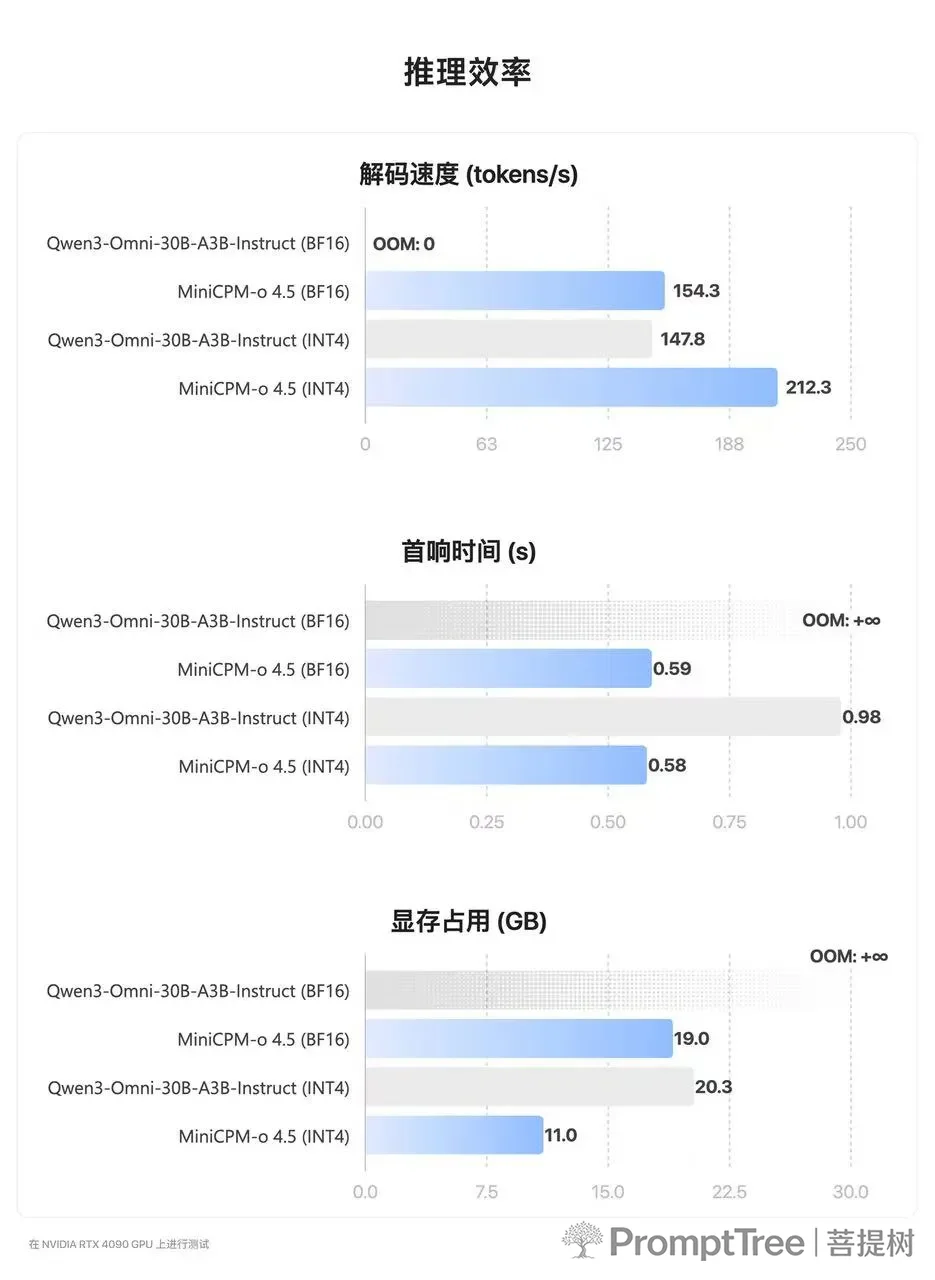
推理效率:在显存方面,MiniCPM-o 4.5 的 INT4 量化版仅需 12GB 显存即可运行,几乎是 Qwen3-Omni INT4 版本的一半,使得其在消费级显卡上的本地部署成为可能。在性能方面,MiniCPM-o 4.5 的推理速度也更快,其 INT4 版本的解码速度达到了 212 tokens/s,比 Qwen3 快了 40% 以上,响应延迟更低。
战略意义
- 解决云端大模型的隐私与延迟痛点:全模态持续交互如果依赖云端,不仅会产生极高的网络延迟,更会带来严重的隐私泄露风险(一直开着麦克风和摄像头)。MiniCPM-o 4.5 将一切运算放在本地,从根本上消除了隐私顾虑,为进入卧室、家庭等私密场景拿到了“通行证”。
- 打开“具身智能”与“万物智能”的想象空间:凭借极高的智能密度、环境感知能力和主动交互能力,MiniCPM-o 4.5 极其适合作为智能座舱(如边开车边帮你主动寻找停车位)、具身智能机器人、甚至智能家居家电的“本地大脑”。
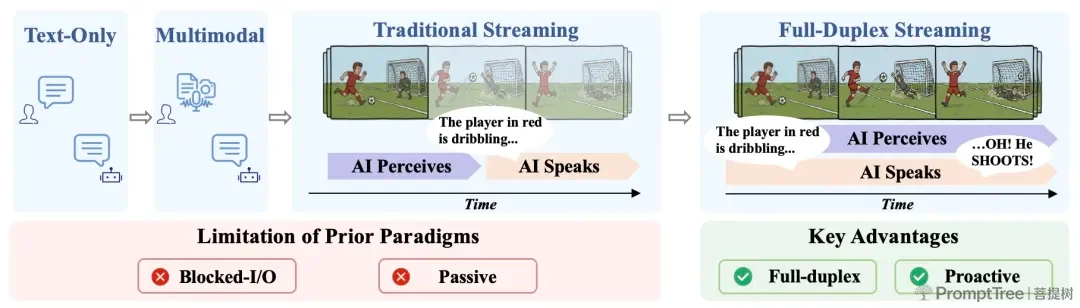
人类交流是流畅、并行的。我们边听边思考,甚至可以打断对方。
但过去,AI 与人类的交互模式是半双工的,像用对讲机:你说完,它才能处理;它说的时候,又听不见你的新指令。
AI 与人类的不同频,使得大多数用户无法在与大模型产品的交互中获得良好的体验感,甚至由于交流的「时空割裂」逐渐失去耐心。长此以往,大模型在多模态场景的落地无疑大大受阻。
不难看出,MiniCPM-o 4.5 并未盲目追逐云端大模型的参数竞赛,而是精准锚定端侧高阶智能这条高价值赛道。这款模型用实力印证:10B 参数量级之内,AI 同样能实现高清多模态深度理解、复杂逻辑推理,以及自然流畅的全双工实时对话体验,综合能力全面拉满。凭借亮眼的综合表现,它已然成为 2026 年端侧开源 AI 领域的标杆之作。
评论的小伙伴,你觉得 「全双工」会成为 AI 交互的下一站吗?