NVIDIA PersonaPlex:支持任意角色与音色的自然对话式人工智能
PersonaPlex与拉贾尔希·罗伊的趣味互动对话
对话式人工智能的发展始终面临一个两难抉择:传统的语音识别→大语言模型→语音合成级联系统,虽支持用户自定义音色与角色,但生成的对话机械生硬,存在尴尬停顿、无法实现插话互动、话轮转换不自然等问题;而Moshi这类全双工模型,首次实现了人工智能的实时听辨与语音生成,让对话变得自然流畅,却只能固定使用单一的音色和角色。NVIDIA PersonaPlex打破了这一取舍困境,用户可从丰富的音色库中选择音色,还能通过文本提示词自定义任意对话角色。无论是需要一位睿智的助手、专业的客服人员、奇幻故事中的角色,还是仅仅想找个聊天的对象,PersonaPlex都能在全程保持用户设定角色的同时,实现极具真实感的自然对话。该模型可灵活处理插话、回应性附和,还原真实的对话节奏,首次让用户同时拥有所需的定制化体验,以及能带来类人交流感受的自然对话效果。
核心能力
全双工交互
PersonaPlex是一款全双工模型,可实现同步听辨与语音生成。这一由Moshi首次提出的能力,让PersonaPlex不仅能学习对话的文字内容,还能掌握与语言表达相关的行为特征,比如何时停顿、何时插话、何时做出回应性附和(如“嗯哼”“哦”等)。
传统级联系统需分别调用语音识别、语言生成、语音合成模型,存在明显的交互延迟,而PersonaPlex通过单模型架构消除了这类延迟:模型会在用户说话的过程中实时更新内部状态,并立即流式生成回应,实现低延迟的人机交互。
为PersonaPlex的输出增添非语言层面的表达特征,使其与无此设计的系统形成了本质的体验差异:该模型能够还原人类交流中用于传递意图、情绪或理解程度的各类语言线索。
应用示例
以下示例展示了PersonaPlex在不同场景下的交互表现。所有音频文件中,左声道为用户语音,右声道(绿色标识)为PersonaPlex的回应语音。
智能助手场景
提示词:你是一位睿智且友善的老师,用清晰、生动的方式解答问题或提供建议。
在全双工基准测试的插话能力评估中,该示例展现了PersonaPlex的通用知识储备、插话交互能力,以及自然的话轮转换表现。
银行客服场景
提示词:你就职于第一神经元银行,姓名为桑妮·维尔塔宁。已知信息:客户在美国家得宝超市的1200美元交易被拒,需核实客户身份;该交易因交易地点异常被标记(交易尝试发生在佛罗里达州迈阿密,客户日常交易地点为华盛顿州西雅图)。
PersonaPlex在该场景中展现了对文本提示词指令的执行能力、共情能力、边听边说的交互能力,以及通过语音提示词实现的口音控制能力。
诊所前台客服场景
提示词:你就职于琼斯医生的诊所,负责接听新患者的咨询电话并记录信息。需记录信息:全名、出生日期、药物过敏史、吸烟史、饮酒史及既往病史;若患者询问,需向其保证信息会严格保密。
该示例体现了PersonaPlex对文本提示词指令的执行能力,以及从用户语音中提取并记录关键信息的能力。
自然的回应性附和
提示词:你乐于开展轻松愉快的对话。
在全双工基准测试的回应性附和能力评估中,PersonaPlex能生成丰富的对话附和语,如“哦好的”“好的”“是啊”“我觉得确实是这样”等,在不打断说话者表达的前提下,传递出主动倾听的状态,且这些附和语的内容和语气都能贴合对话语境。
太空应急场景
提示词:你乐于开展轻松愉快的对话,能围绕火星飞船反应堆堆芯的维修开展专业技术探讨。你是执行火星任务的宇航员,姓名为亚历克斯;当前正遭遇火星任务中的反应堆堆芯熔毁事故,飞船多个系统出现故障,若反应堆持续不稳定,将引发灾难性的故障后果。你需要向对方说明当前情况,并紧急寻求反应堆稳定方案的探讨与帮助。
该示例展现了PersonaPlex对训练分布外文本提示词的强泛化能力(其训练场景主要为助手、客服、开放式日常对话):在长时间的交互中,模型始终保持与文本提示词一致的角色设定,同时还能根据应急场景的需求,表现出恰当的紧张感和急迫感。
模型架构
PersonaPlex通过两类输入定义对话行为,二者协同处理,构建出连贯的角色形象:
- 语音提示词:一种音频嵌入特征,捕捉音色特点、说话风格与韵律特征;
- 文本提示词:用于描述角色身份、背景信息与对话语境的自然语言文本。
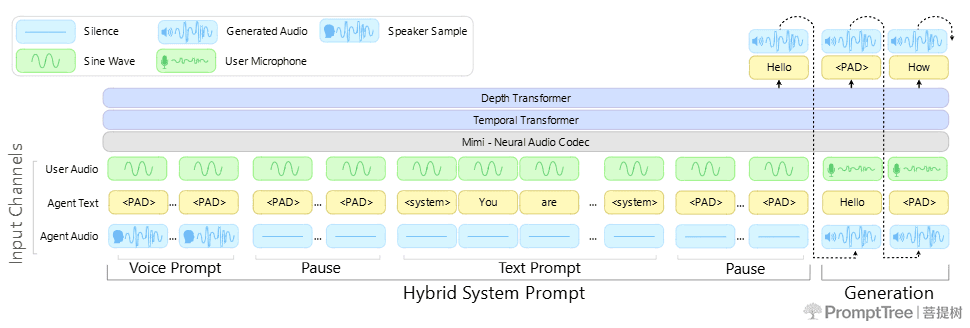
PersonaPlex基于Kyutai实验室的Moshi架构打造,参数量达70亿,核心架构组成如下:
- Mimi语音编码器(卷积神经网络+Transformer):将音频转换为特征令牌;
- 时间Transformer与深度Transformer:负责对话内容的处理;
- Mimi语音解码器(Transformer+卷积神经网络):生成输出语音,音频采样率为24千赫。
模型的双流结构支持同步的听辨与语音生成,还原自然的对话动态;底层搭载Helium语言模型,为模型提供语义理解能力,使其能对训练分布外的场景实现泛化处理。
训练数据
PersonaPlex的设计与训练面临两大挑战:一是缺乏覆盖多元话题、情绪,且包含插话、附和、停顿等丰富非语言行为的对话语音数据;二是全双工模型的监督训练要求训练数据包含多说话者的对话内容,且每个说话者的音频需单独分离。
为解决上述问题,研究团队发现:可利用大语言模型为费舍尔英语语料库中少量无脚本的人类真实对话,回溯生成每位说话者的语境与性格描述,将其转化为角色监督数据。为进一步拓展场景与话题的覆盖范围,团队还通过语言模型生成对话内容与角色提示词,再借助Chatterbox语音合成技术将其转化为音频。PersonaPlex通过单阶段训练,学习这类真实与合成对话数据的混合数据集。
真实对话数据
为学习自然的回应性附和、表情与情绪反馈,PersonaPlex采用费舍尔英语语料库中的7303段真实对话(总时长1217小时)进行训练。研究团队通过GPT-OSS-120B模型为这些对话回溯标注提示词,且提示词的详细程度各有不同,以此平衡模型的泛化能力与指令执行能力,示例如下:
- 你乐于开展轻松愉快的对话。
- 你乐于开展轻松愉快的对话,可围绕居家做饭与外出就餐展开随意探讨。
- 你乐于开展轻松愉快的对话,能围绕职业转变与归属感展开深度交流;你在加利福尼亚州生活了21年,将旧金山视为故乡;你的职业是教师,有丰富的旅行经历;你不喜欢参加会议。
助手与客服角色的合成对话数据
PersonaPlex的训练数据还包含39322段助手角色的合成对话(总时长410小时),以及105410段客服角色的合成对话(总时长1840小时)。其中,对话文本由Qwen3-32B与GPT-OSS-120B模型生成,对话音频由Chatterbox语音合成技术生成。
在问答助手场景中,研究团队会变换用户与模型的音色及对话内容,所有助手交互均使用统一的固定文本提示词:你是一位睿智且友善的老师,用清晰、生动的方式解答问题或提供建议。
在客服场景中,除变换音色与对话内容外,研究团队会为模型提供包含角色履职所需全部关键信息的文本提示词,包括机构名称、角色类型、姓名及其他背景信息(如定价、营业时间、规则等),示例如下:
- 你就职于城市环卫服务公司,姓名为阿耶伦·卢塞罗。已知信息:需核实客户奥马尔·托雷斯的身份;当前服务周期为隔周一次;下次垃圾清运时间为4月12日;可加购堆肥箱服务,每月8美元。
- 你就职于耶路撒冷沙克舒卡餐厅,姓名为欧文·福斯特。已知信息:餐厅提供两款沙克舒卡菜品——经典款(水波蛋,9.5美元)、辣味款(墨西哥辣椒炒鸡蛋,10.25美元);配菜包含热皮塔饼(2.5美元)、以色列沙拉(3美元);无套餐优惠;外带窗口营业至晚9点。
- 你就职于航空无人机租赁专业公司,姓名为托马兹·诺瓦克。已知信息:公司可租赁机型及定价——凤凰无人机X(4小时65美元,8小时110美元)、高端光谱无人机9(4小时95美元,8小时160美元);押金要求——标准机型150美元,高端机型300美元。
合成数据让模型具备任务执行能力,而费舍尔英语语料库中的真实对话,包含当前语音合成系统难以精准模拟的多元自然交互模式。研究团队为真实与合成数据采用统一的文本和语音提示词格式,最大化提升模型拆解两类数据特征并融合运用的能力。
关键研究发现
从PersonaPlex的训练实验中,研究团队得出以下核心结论:
- 基于预训练基础模型的高效定制化:以Moshi的预训练权重为基础,仅通过5000小时以内的定向数据训练,即可让模型具备任务执行能力。预训练的Moshi模型已拥有较强的通用对话能力,微调过程不仅能保留这些能力,还能为模型增添通过提示词引导交互行为的新能力。
- 语音自然度与任务执行能力的解耦实现:合成训练数据的文本提示词与对话内容覆盖了多元的性格设定和场景,但合成音频无法还原真实录音的行为丰富度与真实感;费舍尔语料库的对话虽在文本提示词和无导向对话的领域多样性上存在局限,但其录音包含丰富的语音表达模式。最终训练得到的PersonaPlex,既具备费舍尔语料库中的自然语音表达模式,又拥有合成数据赋予的任务执行能力。通过融合两类数据,研究团队以通用混合提示词和语音条件约束为桥梁,实现了模型任务知识与自然交互模式的结合。
- 超越训练领域的涌现式泛化能力:论文中的实验验证了模型处理新场景、新语境的能力,发现其能调取并运用语境信息对新场景做出回应。尽管PersonaPlex的训练仅覆盖服务与助手场景,但上述火星宇航员的示例证明,模型可对预设场景外的内容实现泛化处理:能熟练使用技术危机管理的专业词汇,表现出恰当的情绪急迫感,还能开展反应堆物理相关的领域专属推理——这些内容均未出现在训练数据中。研究团队推测,这种泛化能力源于Moshi的底层语言模型Helium预训练时使用的大规模通用语料库。
模型评估
在对话式人工智能通用基准测试与自研的客服基准测试中,PersonaPlex在对话动态表现、回应与插话延迟、任务执行能力上均优于其他开源及商用系统,且在问答助手和客服两类角色中均保持优异表现。
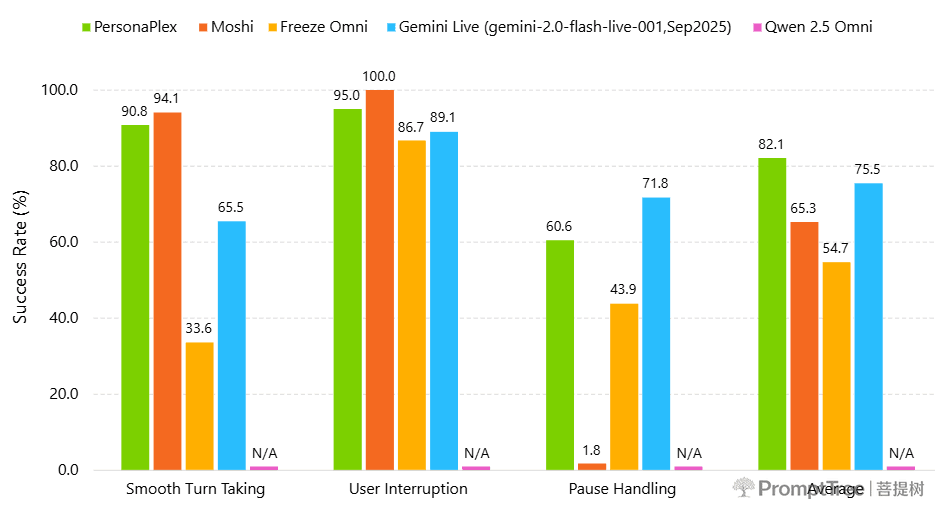
评估维度与指标
- 对话动态表现(分值越高越好):包含话轮转换流畅度、用户插话处理能力、停顿处理能力三个子指标,以成功率为量化标准;
- 交互延迟(数值越低越好):包含话轮转换流畅度、用户插话处理场景下的延迟,以及平均延迟,以秒为量化单位;
- 任务执行能力(分值越高越好):由GPT-4o大语言模型作为评估裁判,在全双工基准测试、服务双工基准测试及平均得分三个维度进行评分,满分5分。
评估基准
为量化PersonaPlex与其他对话式人工智能模型的性能差异,研究团队首先采用成熟的全双工基准测试(FullDuplexBench)进行评估,该基准主要针对话轮转换、用户插话、停顿处理等对话动态指标进行测评,同时由GPT-4o对模型的回应质量进行打分。
由于全双工基准测试仅针对通用问答助手角色的回应内容进行评估,研究团队对其进行了拓展,打造了服务双工基准测试(ServiceDuplexBench),实现了对真实场景下各类客服角色任务执行能力的评估。
参与对比的模型包括:Moshi、Freeze Omni、Gemini Live(gemini-2.0-flash-live-001,2025年9月版本)、通义千问2.5 Omni(Qwen 2.5 Omni),PersonaPlex在各核心评估维度均表现领先。
开源与可用情况
- PersonaPlex的代码基于MIT许可证开源,模型权重基于NVIDIA开放模型许可证发布;基础Moshi模型由Kyutai实验室开发,基于CC-BY-4.0许可证开源。
- 服务双工基准测试(ServiceDuplexBench)将在近期正式发布。
致谢
PersonaPlex基于Kyutai实验室的Moshi模型研发,本研究的开展得益于该模型的开源发布。
引用说明
若你的研究中使用了PersonaPlex模型,请引用相关论文(BibTeX引用格式即将发布)。